2021. 1. 29. 17:55ㆍ데이터 분석/통계분석
이번 글은 가설 검정에 대해 내용을 다뤄보겠습니다. 가설 검정은 통계적으로 검증의 대상이 되는 가설을 검정하는 것을 말합니다.
귀무가설, 대립가설
통계적으로 가설을 세울 때 귀무가설(H0), 대립가설(H1) 두가지 가설을 설정합니다.
귀무가설은 "모수가 특정한 값이다" 또는 "두 모수의 값은 값다" 등과 같이 판단이 옮다는 가정 하에 설정하는 가설이고 대립가설은 귀무가설을 반박하는 가설로 "모수가 특정한 값이 아니다" 또는 " 두 모수의 값은 다르다" 와 같은 가설입니다.
검정통계량
검정통계량은 통계적 가설의 진위 여부를 검정하기 위해 표본으로부터 계산하는 통계량을 말합니다. 검정통계량의 값이 어떤 기준을 벗어나는지 확인하여 가설의 진위여부를 결정합니다. 검정통계량을 구하기 위해서는 먼저 데이터의 분포를 정규분포, t-분포, 카이제곱분포, F분포 등 어떤 분포를 따르는지 미리 가정해야합니다. 가정된 분포 하에 검정통계량을 산출합니다.
유의수준
표본으로부터 모집단의 정보를 예측할 때 100% 확실하게 예측할 수 있는 것이 아니기 때문에 오차를 고려해야합니다. 이때 틀릴 확률 즉, 귀무가설이 옳은데도 불구하고 이를 기각하는 확률의 크기를 유의수준이라고 합니다. 유의수준은 검정통계량을 구하는 것과는 무관하게 검정을 실시하는 사람의 판단에 따라 결정합니다. 보통 유의수준은 1%, 5%, 10%를 주로 이용합니다.
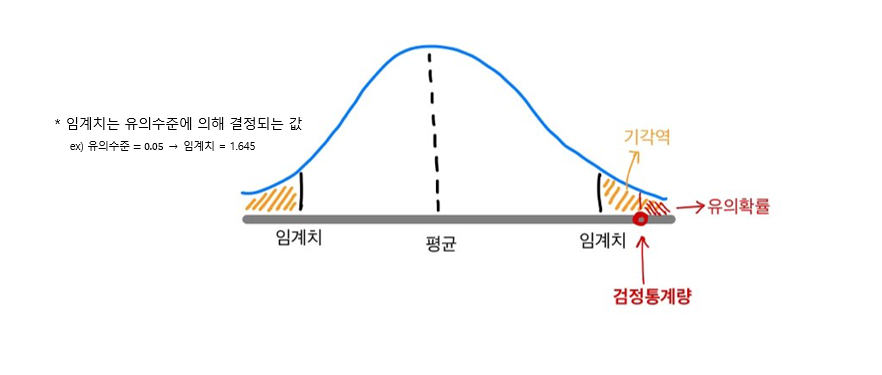
기각역
유의수준 a가 정해졌을 때, 검정통계량의 분포에서 이 유의수준의 크기에 해당하는 영역을 귀무가설이 기각되는 영역(대립가설을 채택하는 영역)이라고 하는데 이를 기각역이라고 합니다.
이를 그림으로 나타내면 다음과 같습니다.
가설 검정 단계
1. 가설 세우기
- 귀무가설 기각을 쉽게하려면 유의수준을 크게하여 기각역을 넓게 만들 수 있음. 그럼 대립가설을 채택할 가능성이 높아짐.
2. 유의수준 결정
3. 귀무가설이 옳다는 전제 하에 검정통계량을 구함.
4. 검정통계량 값이 기각역에 속하는 가를 판단하고 기각역에 속하면 귀무가설을 기각하고 그렇지 않으면 귀무가설을 채택한다.
4-(1). 검정통계량 값이 기각역에 속하는 지 수치상으로 알 수 없기 때문에 유의확률을 이용하여 구하는데 유의확률은 검정통계량에 의해 결정되는 구간으로 제 1종 오류가 발생환 확률임.
-> 유의확률(p-value)<유의수준: 귀무가설을 기각하고 대립가설을 채택.
-> 유의확률(p-value)>유의수준: 귀무가설을 채택하고 대립가설을 기각.
양측검정, 단측검정
가설을 세울 때 검정하는 방식에는 양측검정과 단측검정으로 나뉩니다. 예를 들면 다음과 같은 가설을 세울 수 있습니다.
- 양측검정
- H0: 모수의 평균은 0이다.
- H1: 모수의 평균은 0이 아니다.

- 단측검정
- H0: 모수의 평균은 0이다.
- H1: 모수의 평균은 0보다 작다.(좌측검정) or 모수의 평균은 0보다 크다.(우측검정)

가설검정 결과의 오류
가설검정은 확률을 기반으로 하기 때문에 오류의 가능성을 갖고 있습니다. 오류의 내용은 다음과 같습니다.
- 제 1종 오류: 귀무가설이 참임에도 기각하는 오류(유의확률)
- 제 2종 오류 귀무가설이 거짓임에도 채택하는 오류
참고
'데이터 분석 > 통계분석' 카테고리의 다른 글
| [통계분석] 05. 범주형 변수, 어떤 검정을 할 수 있을까? (0) | 2021.02.02 |
|---|---|
| [통계분석] 04. 연속형 변수, 어떻게 가설 검정을 할까? (0) | 2021.01.29 |
| [통계분석] 02.모수를 왜 추정하고, 어떻게 추정하는거지? (0) | 2021.01.29 |
| [통계분석] 01. 확률분포는 머신러닝에서 어떻게 사용될까? (1) | 2021.01.29 |
| [통계분석] 08. 관측 데이터를 잘 설명할 수 있는 잠재 공간을 발견하는 법? - PCA (0) | 2020.12.09 |