2021. 2. 1. 21:56ㆍML&DL
이번 글은 순천향대학교 정영섭 교수님의 강의와 핸즈온 머신러닝 2판을 공부한 후 정리한 내용입니다. 비지도 학습에 속하는 군집화에 대해 알아보겠습니다.
순서
1. 비지도 학습
2. 군집화
3. K-means
3.1. 작동 과정
3.2. 최적의 클러스터 개수를 선택하는 방법
4. 계층적 군집화(Hierarchical Clustering)
5. DBSCAN
1. 비지도 학습
비지도 학습은 label이 없는 데이터를 이용하는 알고리즘입니다. 데이터 시각화, 데이터 압축, 데이터 소거에 이용할 수 있고 입력 데이터로만 흥미로운 변환을 찾거나 데이터의 상관관계를 더 잘 이해합니다. 지도 학습 문제를 해결하기 전에 데이터셋을 이해하는데 도움을 받을 수도 있습니다. 대표적인 예로 군집화, 이상치 탐지, 밀도 추정에 사용합니다. 그중 군집화에 대한 내용입니다.
2. 군집화

군집화는 비지도 학습에 속하는 알고리즘으로 비슷한 샘플을 하나의 클러스터로 모으는 것입니다. 비슷한 행동을 하는 고객을 동일한 클러스터로 분류하는 고객 분류, 동일한 클러스터 내의 고객들이 좋아하는 컨텐츠를 추천하는 추천 시스템, 제시된 이미지와 비슷한 이미지를 찾아주는 검색 엔진, 차원 축소를 이용하여 분석을 위한 충분한 정보를 가질 수도 있습니다. 또한 이상치도 탐지할 수 있습니다. 만약 레이블 된 샘플이 적다면 군집화를 이용하여 클러스터를 만들고 동일한 클러스터에 있는 모든 샘플에 동일한 레이블을 부여하여 지도 학습의 성능을 높일 수도 있습니다. 정말 다양하게 사용할 수 있지 않나요? 정말 유용한 알고리즘입니다.
그렇다면 군집화 어떻게 구현되는 걸가요? 군집화는 비계층적 군집화(Partitioning Clustering), 계층적 군집화(Hierarchical Clustering) 2가지가 있습니다. 비계층적 군집화는 사전에 군집의 수를 정해주는 방법, 계층적 군집화는 각 개체가 독립적인 각각의 군집에서 점차 거리가 가까운 대상과 군집을 이루는 방법입니다. 비계층적 군집화는 또 중심 기반과 밀도 기반 군집화로 나뉘는데 중심 기반 군집화의 대표적인 알고리즘은 K-means, 밀도 기반 군집화의 대표적인 알고리즘은 DBSCAN이 있습니다. 각 군집 알고리즘의 구현 방식을 알아보겠습니다.
3. K-means
K-means알고리즘은 샘플 데이터를 k개의 cluster로 묶는 iterative 한 알고리즘입니다. 각 cluster 내 유사도는 높이고 외 유사도는 낮추는 것을 가정으로 각 cluster 거리 차이의 분산을 최대화하는 것이 목적입니다. 이 알고리즘은 EM알고리즘을 기반으로 작동합니다. EM알고리즘의 E는 Expectation, M는 Maximization으로 기대치를 최대화하는 것입니다. 이때 임의의 likelihood를 최대화하는 알고리즘으로 주로 비지도 학습에 사용되는 학습용 알고리즘입니다. Uniform distribution으로 초기 파라미터 세터를 입력으로 주고 E-step과 M-step을 계속 반복하면 더 이상 파라미터가 변하지 않는 수렴 상태에 이릅니다. (optimal 한 세타값을 구함.) 결국, EM 알고리즘의 목표는 임의의 값을 설정한 후 그 값을 계산하여 M-step에서 우리가 원하는 값을 찾기 위해 업데이트하는 것으로 Likelihood를 최대화시키는 파라미터를 찾는 것이 목적입니다. (MLE랑 다름 주의)
3.1. 작동과정
이를 이용한 K-means의 작동 과정은 다음과 같습니다.

1. 임의의 k를 정한다.
2. k개의 cluster centroid(cluster의 중심이 되는 특정 포인트)를 임의로 선택한다.
3. 각 샘플의 레이블을 가장 가까운 centroid에 해당하는 클러스터 레이블로 할당한다. (E-step)
- 거리를 구하는 Distance function은 Euclidean distance를 많이 사용하지만 Mahalanobis distance, Cosine Similarity, KL divergence 등 여러가지 거리 함수들이 존재.
- Euclidean distance는 각 차원의 가리별로 차이 값을 구한 뒤 제곱하여 더 더하는 방법
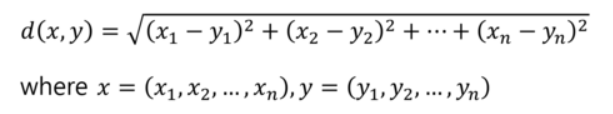
- Euclidean distance 에서 데이터의 속성들의 공분산을 반영하여 거리를 계산하는 방법으로 상관관계가 큰 방향으로의 거리는 적게 반영함.

4. 각 클러스터에 속한 샘플들의 평균을 계산하여 모든 centroid를 업데이트한다.(M-step)
5. centroid의 값의 변화가 없을 때까지 3과 4번을 반복합니다.

EM알고리즘은 전역 최적점을 구한다는 보장이 없습니다. 지역적 최적점으로 수렴하도록 하기 위해 초기 센트로이드를 잘 설정하는 것이 중요합니다. "이너셔"라고 하는 각 샘플과 가장 가까운 센트로이드 사이의 평균 제곱 거리를 이용하여 최선의 설루션을 반환할 수 있습니다. 평균 제곱 거리가 낮을수록 좋기 때문에 이너셔가 낮은 모델이 좋은 모델입니다.
두 점 사이의 직선은 항상 가장 짧은 거리가 되는 삼각부등식을 이용하여 불필요한 계산을 많이 피할 수 있습니다. 샘플과 centroid 사이의 거리를 위한 하한선과 상한선을 유지합니다. k-means 변종 알고리즘으로 k-means를 사용할 때 전체 데이터셋을 사용해 반복하는 ㄴ것이 아닌 각 반복마다 미니 배치를 사용해 centroid를 이동할 수 있는 방법도 있습니다. 하지만 이 방법은 초기화를 여러 번 수행하고 만들어진 결과에서 가장 좋을 것을 직접 골라야 하는 수고스러움이 있습니다. 미니 배치 k-means알고리즘은 일반 k-means알고리즘보다 훨씬 빠르지만 이너셔를 계산하면 값이 더 높게 나옵니다. 하지만 훨씬 빠르다는 장점이 있기 때문에 사용하는 것이 좋습니다.
3.2. 최적의 클러스터 개수를 선택하는 방법
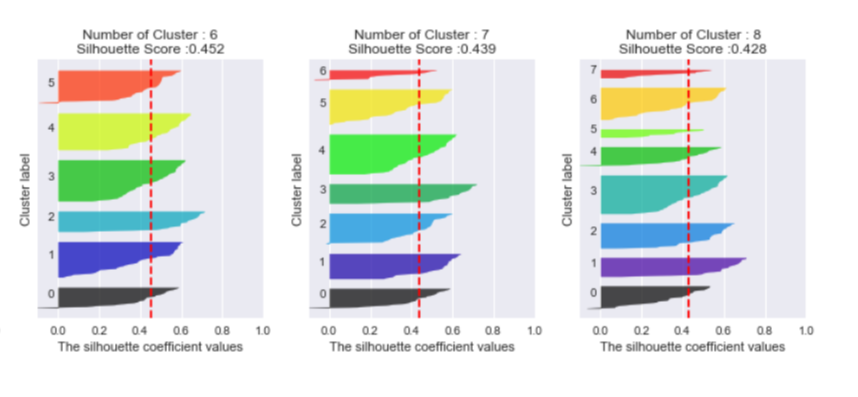
최적의 클러스터 개수 k는 어떻게 찾을 수 있을까요? 첫 번째 방법은 실루엣 점수라는 방법을 이용합니다. 모든 샘플에 대한 실루엣 계수의 평균을 계산하는 방법으로 (b-a)/max(a,b)의 평균을 계산합니다. a는 동일한 클러스터에 있는 다른 샘플까지의 평균 거리, b는 가장 가까운 클러스터까지의 평균 거리입니다. 실루엣 계수는 -1~1까지의 값을 가지고 1에 가까울수록 cluster가 잘 나눠진 것입니다.
실루엣 계수를 할당된 클러스터와 계숫값으로 정렬하여 그래프를 그릴 수 있는데 이를 실루엣 다이어그램이라고 합니다. 실루엣 다이어그램을 보고 클러스터 개수를 설정하는 것이 좋습니다. 높이는 클러스터가 포함하고 있는 샘플의 수, 너비는 클러스터에 포함된 샘플의 정렬된 실루엣 계수를 나타냅니다. 빨간 선은 각 클러스터 개수에 해당하는 실루엣 점수로 이 선보다 안쪽에 있는 것은 클러스터 내 샘플이 다른 클러스터랑 너무 가깝다는 것을 의미하기 때문에 대부분 빨간 선을 넘고 1.0에 근접해있는 것이 좋습니다.
두 번째 방법은 Rule of Thumb라는 방법인데 이는 데이터 수가 n개일 때 root(n/2) 개의 클러스터를 설정한다는 방법이 있습니다. 세 번째 방법은 Elbow method로 여러 후보 k값들에 대해 cluster들의 적절함을 평가합니다. 즉, 순차적으로 cluster의 수를 늘려가면서 가장 좋은 것을 사용하는 것입니다. 네 번째 방법은 Information Criterion Approach방법으로 클러스터링 모델에 대해 likelihood를 계산하여 활용합니다. 예를 들어 Gaussian Mixture Model을 활용하여 likelihood를 계산할 수 있습니다. 마지막 방법은 계층적 군집화 결과를 활용하여 최적의 개수를 짐작하는 것입니다. (계층적 군집화 결과 동작 방식은 스크롤을 내리시면 있습니다.) 결국 최적의 k를 구한다는 것은 응집도가 높은 것(분산이 낮은 것)을 구하는 것입니다.
k-means는 클러스터의 크기나 밀집도가 서로 다르거나 구형이 아닐 경우 잘 작동하지 않기 때문에 feature normalization이 필요합니다. feature normalization이 잘되어있어야 distance function의 결과가 좋게 나올 수 있습니다. 이상치에 취약하기 때문에 이상치를 제거하기 위한 전처리를 하거나 평균을 계산하지 않고 데이터 중에서 하나를 중심으로 사용하는 K-medoids 알고리즘을 사용합니다. 이처럼 데이터에 따라서 잘 수행할 수 있는 군집 알고리즘은 다릅니다. 만약 데이터의 분포가 타원형이라면 Gaussian Mixture Model이 더 잘 작동할 수 있습니다.
4. 계층적 군집화(Hierarchical Clustering)

계층적 군집화는 k-means와 달리 임의의 k를 설정할 필요가 없습니다. 각 데이터들을 cluster라고 가정하고 각 데이터의 pair 사이의 거리를 계산합니다. 거리가 가장 가까운 pair를 하나의 cluster로 묶고 모든 데이터가 하나의 cluster로 묶이지 않으면 다시 각 데이터의 pair 사이의 거리를 계산합니다. 모든 데이터가 하나의 클러스터가 될 때까지 반복합니다. 이때, K-means와 마찬가지로 어떤 거리 함수를 사용하느냐에 따라 다른 결과가 나타납니다.
클러스터 사이의 거리를 측정해서 거리가 가장 가까운 pair를 하나의 cluster로 묶는데 어디를 기준점으로 거리를 측정할 것인지 결정해야합니다. 이를 어떤 linkage방법을 사용할 것인가라고 합니다.

Single linkage는 단순히 가장 가까운 cluster를 연결하는 방법이고 Complete linkage는 가장 먼 cluster를 연결하는 방법입니다. Average linkage는 각 cluster내의각점에서다른 cluster내의 모든 점 사이의 거리에 대한 평균을 사용하는 방법입니다.
linkage 방식에 따라서도 다른 결과를 나타내기 때문에 데이터의 분포에 맞춰 적절한 방법을 적용하는 것이 좋습니다. (Average linkage 방식이 가장 성능이 좋은 편이었다는 연구결과가 있기도 합니다만)
계층적 군집화는 시각적 관점으로 해석하기에 아주 용이한 덴드로그램으로 표현할 수 있다는 장점을 갖고 있지만 시간 복잡도가 약 O(n^2)입니다. 또한 계층 구조이기 때문에 이전 단계에서 잘못 판단할 경우 수정할 수 없습니다. 덴드로그램을 보고 데이터에 따라 원하는 군집 개수를 정할 수 있기 때문에 효용가치가 높은 알고리즘입니다.
5. DBSCAN

밀집된 연속적 지역을 cluster로 정의하는 밀도기반 군집화 알고리즘입니다. K-means의 단점이 구형 형태의 cluster 외에는 잘 작동하지 않는다는 것이었습니다. 하지만 DBSCAN은 어떤 형태의 모양이라도 잘 작동하고 앞서 보았던 알고리즘들과 달리 어떤 cluster에도 들어가지 않는 데이터들도 있습니다. 또한 사전에 cluster의 개수를 지정해주지 않아도 됩니다. DBSCAN의 가정은 cluster내의 데이터들의 밀도가 높고 군집에 해당하지 않는 밀도는 낮다는 가정을 합니다.
알고리즘의 동작 과정은 다음과 같습니다.
1. 각 샘플에서 작은 거리인 epsilon 내에 샘플이 몇 개 놓여있는지 셉니다. 아래 동그란 군집 내 샘플을 epsilon-neighborhood라고 부릅니다.
- epsilon은 한 쌍의 점 사이의 최대 거리입니다.

2. epsilon-neighborhood 내에 적어도 min-sapmles개 샘플이 있다면 이를 core instance로 간주합니다. 이 cluster 내 샘플들은 밀집된 cluster에 있는 샘플입니다.
3. core instance 이웃에 있는 모든 샘플은 동일한 cluster에 속합니다. 이웃에는 다른 core instance가 포함될 수 있습니다. 따라서 core instance 이웃의 이웃은 하나의 cluster를 형성합니다. 아래 그림을 보시면 이웃의 이웃이 하나의 cluster를 형성한다는 것이 어떤 것인지 이해 가시죠?!

4. 이때 core instance에 속하지 않고 이웃하지도 않는 샘플을 noise라고 판단합니다. border instance는 core instance의 이웃에는 포함이 되나 epsilon 반경 내 점이 min-sample 수 인 4개가 되지 않아 밀집된 군집에 속한다고 보기 어려운 샘플들입니다.


DBSCAN은 앞서 말한 장점 외에도 이상치에 안정적이고 하이퍼파라미터가 eps, min_samples 뿐입니다. 하지만 cluster간의 밀집도가 크게 다르면 모든 cluster를 올바르게 잡아내는 것이 불가능하고 계산 복잡도는 약 O(mlogm)입니다.
그림 출처
[1] [R 군집분석 (Cluster Analysis)] (1) 응집형 계층적 군집화 : (1-1) 단일(최단) 연결법(Single link, MIN)
[2] Martin Ester, Hans-Peter Kriegel, Jorg Sander, and Xiaowei Xu. 1996. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD 96). AAAI Press. pp. 226–231.
[3] k-평균 알고리즘 위키백과
[4] DBSCAN
'ML&DL' 카테고리의 다른 글
| [ML] NMF(Non-negative Matrix Factorizaion), 비음수 행렬 분해 (2) | 2021.04.17 |
|---|---|
| [ML] 유사도 검정 (2) | 2021.04.06 |
| [ML] 직관적인 모델 의사결정나무와 강한 학습기 앙상블 (0) | 2021.01.31 |
| 심층 신경망 훈련하기 - 학습 속도를 높이는 방법 (0) | 2020.12.29 |
| 심층 신경망 훈련하기 - 레이블 된 데이터가 적을 때 복잡한 문제를 다루는 데 도움이 되는 전이 학습과 비지도 사전 훈련 하는 방법 (0) | 2020.12.29 |