2021. 4. 17. 17:49ㆍ자료구조
이번 글은 하나의 문제는 단 한 번만 풀도록 하는 효율적인 알고리즘, Dynamic Programming에 대해 다룹니다.

동적 계획법(DP, Dynamic Programming)은 한 번 푼 문제는 저장해놓고 공간복잡도를 늘리는 대신 시간복잡도는 줄이는 방식입니다. 지난 포스팅에서 합병 정렬과 퀵 정렬을 하며 다뤘던 분할 정복 방식(Divide and Conquer)과 유사한 알고리즘입니다. 분할 정복 방식도 문제를 더 작은 문제로 나눠서 풀었었죠? 동적 계획법도 비슷한 조건을 갖고 있습니다.
DP를 적용하기 위한 2가지 조건입니다.
1. 최적 부분 구조(Optimal Substructure)
- 전체 문제의 답을 부분 문제의 답을 이용하여 풀 수 있는 구조
2. 중복되는 부분 문제(Overlapping subproblem)
- 부분 문제들에 중복되는 부분들이 있는 문제
합병정렬이나 퀵 정렬에서도 문제들이 중복되지 않나? 그럼 이것도 동적 계획법을 적용할 수 있는 건가?라고 생각하실 수 있지만 동작 과정만 같을 뿐 문제의 답이 겹치지 않기 적용할 수 없습니다. 왼쪽 반, 오른쪽 반을 해결하는 과정은 완전히 독립적으로 중복되지 않는 문제(Non-overlapping Subproblem)입니다. 즉, DP는 작은 부분 문제의 답이 항상 같아야합니다. 그럼 이렇게 중복되는 부분 문제의 비효율을 어떻게 줄일 수 있는 걸까요? 한 번 계산한 결과는 다시 활용해서 문제를 해결하는 방식입니다.

DP가 동작하는 방법은 Memoizaition과 Tabulation이 있습니다.
1. Memoizaition
- 중복되는 계산은 한 번만 계산하는 재귀 방식
2. Tabulation
- 답을 구하기 위한 모든 계산을 Table 방식으로 저장하는 for문 방식
두 방식의 장단점은 명확합니다. Memoizaition은 재귀 방식이기 때문에 너무 많이 사용하면 call stack이 쌓이고 과부하로 오류를 발생할 가능성이 있지만 위에서부터 계산하는 Top-Down 방식이기 때문에 필요 없는 계산은 하지 않아도 됩니다. Tabulation은 반복문으로 계산하는 Bottom-Up 방식은 과부하로 인한 오류가 생길 일이 없지만 필요없는 것까지도 계산하게 된다는 단점을 갖고 있습니다.
피보나치수열을 이용하여 Memoization과 Tabulation 방식을 비교해보겠습니다.
fib(6)을 구하기 위해 fib(5)와 fib(4)를 더하죠.
그리고 fib(5)를 구하기 위해 fib(4)과 fib(3)을 구합니다. 이를 그림으로 나타내면 아래와 같죠.
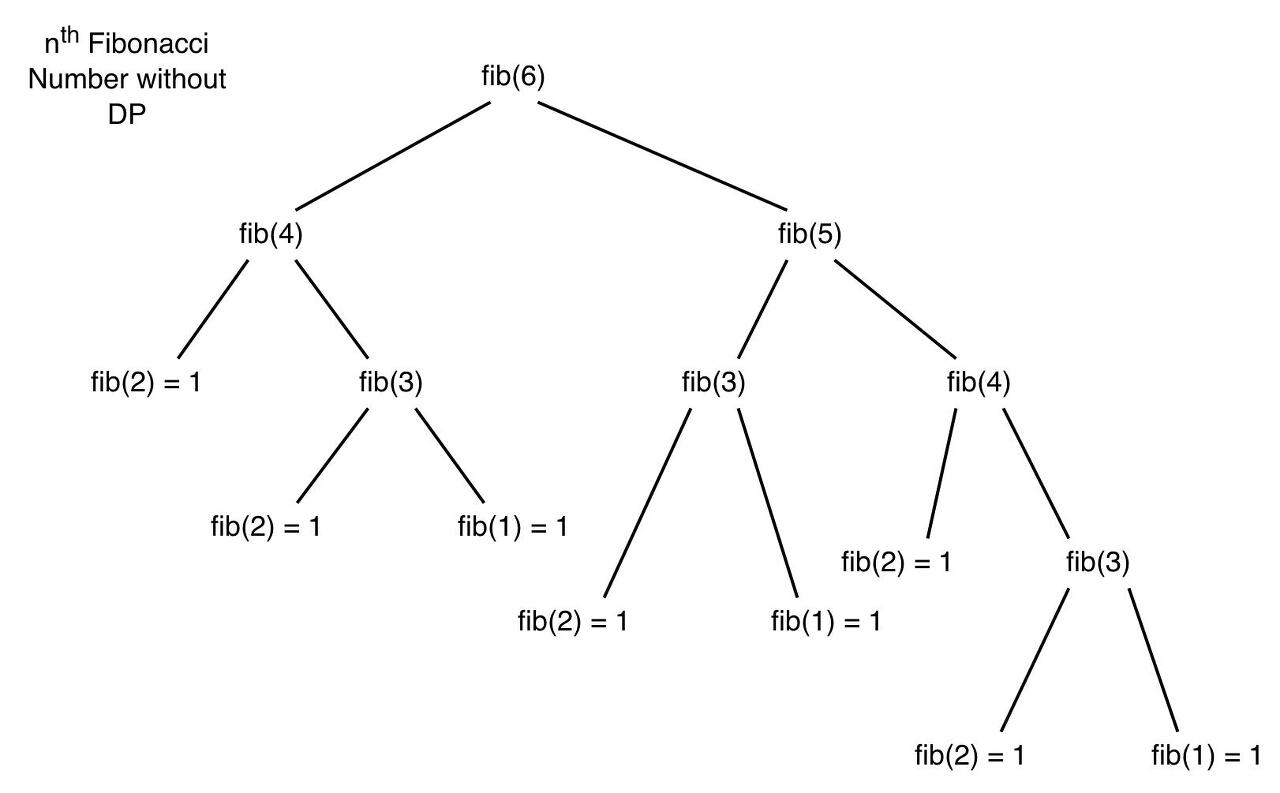
동작하는 과정을 보면 동일한 값들의 계산이 반복됩니다.
Memoization
이제 이 과정을 한 번만 계산하고 메모한 후 메모를 참고하겠습니다. 아래와 같이 한 번 계산한 빨간 박스 부분의 값들이 캐시(다시 사용할 값들을 저장해놓는 공간)에 저장되고 나머지 값들은 캐시에서 가져다 쓰게 됩니다.

Memoization 방식은 재귀 방식이라고 앞서 말씀드렸습니다. 재귀 방식을 사용하기 위해 base case와 recursive case를 나눠야 합니다.

피보나치수열에서 base case는 fib(1), fib(2)입니다. 항상 1의 값을 갖죠. recursive case는 N이 1, 2 가 아닐 때 fib(N) 구하는 경우입니다. fib(N-1) + fib(N-2)의 수식을 가지죠. 이를 점화식이라 부르고 DP는 규칙을 찾아 점화식을 세워 접근하는 것이 좋습니다. 이를 코드로 나타내면 아래와 같습니다.
# N번째 피보나치 수를 찾는 함수
def fib_memo(N, cache):
# base case (N = 1, 2일 때 피보나치 수는 1)
if N < 3:
return 1
if N not in cache.keys():
cache[N] = fib_memo(N-1, cache) + fib_memo(N-2, cache) # 재귀를 통해 피보나치 수 찾기
return cache[N]
# N번째 피보나치 수를 담는 사전 함수
def fib(N):
fib_cache = {}
return fib_memo(N, fib_cache)
Tabulation
Tabulation은 fib(6)을 구하기 위해 아래와 같이 table에 6보다 작은 모든 값의 for문으로 피보나치 수를 저장한 후 fib(6)을 구하기 위해 필요한 값을 가져다 사용하는 것입니다.

def fib(N):
fib_table = [0, 1, 1]
for i in range(3, N + 1):
fib_table.append(fib_table[i - 1] + fib_table[i - 2])
return fib_table[N]
Tabulation방식은 시간복잡도가 O(N) 공간복잡도도 O(N)입니다. 하지만 리스트를 사용하는 대신 가장 최근 값들을 저장하는 변수 두 개를 활용하여 공간 복잡도를 줄일 수 있습니다. 예를 들어 fib(5)를 계산하기 위해 fib(4)와 fib(3)만 알면 되죠. 그럼 가장 최근 값을 나타내는 fib(4)가 담을 변수(current), 그 직접 값을 나타내는 fib(3)을 담을 변수(previous)를 선언합니다. 하지만 Tabulation방식은 Bottom-Up방식이므로 current, previous 각 초기값을 1, 0으로 시작한 후 갱신하는 방식으로 반복합니다. 이를 코드로 나타내면 아래와 같습니다.
def fib_fun(N):
current = 1
previous = 0
for i in range(1, N): # currnet = 1로 초기화했기 때문에 1부터 for문
current, previous = current + previous, current # 따로 임시 저장 변수 설정하지 않고 값을 저장
return current
참고
'자료구조' 카테고리의 다른 글
| [Algorithm] 탐욕적인 알고리즘, Greedy (0) | 2021.05.01 |
|---|---|
| [Algorithm] 정렬 (0) | 2021.04.05 |
| [Algorithm] 가능한 모든 경우의 수를 시도하는 순진한 알고리즘, Broute Force? (0) | 2021.03.21 |
| [Algorithm] 선형 구조에서의 탐색, 선형탐색과 이진탐색 (4) | 2021.03.21 |
| [Algorithm] 그래프(Graph) (0) | 2020.11.22 |