2020. 4. 29. 17:37ㆍ데이터 분석/비정형데이터분석
시간에 따라 변하는 신호의 패턴이 갑자기 변하는 구간. 즉, 급격한 변화를 탐지하는 방법입니다.
시계열 데이터는 어떤 변화를 감지할 것인가? 관점에서 평균 또는 분산, 평균과 분산이 변하는 구간을 찾아내어 변화하는 위치를 하나의 특성값으로 간주하여 tidy data 형태로 만들 수 있습니다. 이렇게 변하는 구간은 changepoint 패키지를 이용하여 찾아냅니다. 난수를 생성하여 신호데이터를 만들어 급격하게 변하는 곳을 찾아보도록 하겠습니다.
library(changepoint)평균의 변화량이 발생하는 시점
- cpt.mean(data): 평균의 변화량이 발생하는 시점에 관한 내용이 객체로 반환
- cpts(cpt.mean(data)): 평균의 변화량이 발생하는 시점을 벡터로 반환
# 다음번에도 같은 난수가 발생하도록 seed 설정
set.seed(1) 확률밀도함수인 정규분포를 이용하여 난수 생성를 생성합니다. 정규분포 파라미터는 평균과 분산 2가지로 평균이 0이고 분산이 1인 난수와 평균이 5이고 분산이 1인 난수, 평균이 15이고 분산이 1인 난수를 생성하여 데이터를 만듭니다.
m1 = c(rnorm(100,0,1),rnorm(100,5,1),rnorm(100,15,1)) time = 1:length(m1) # 난수 100+100+100개로 총 300개의 시간 값 생성
plot(time,m1,"l") # 시계열 패턴을 보기 위해 line으로 그림
# 평균의 변화
m1.amoc = cpt.mean(m1) # 평균의 변화량이 발생하는 시점에 관한 내용이 객체로 반환됨.
cpts(m1.amoc) # 몇번째에서 변화량이 발생했는가를 나타내는가로 벡터로 반환됨.
plot(m1.amoc) # 평균값을 line그래프로 나타내줌.
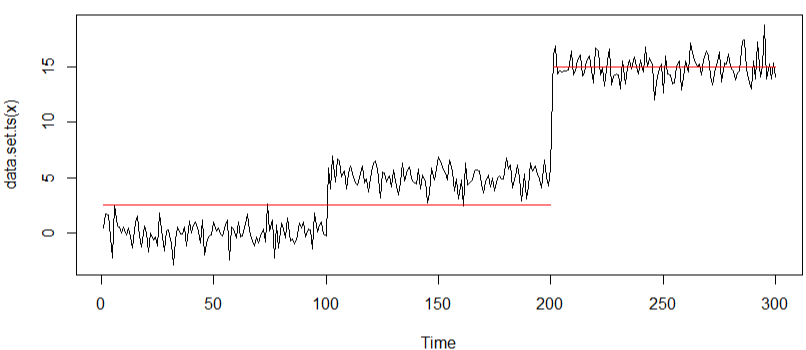
Changepoint Locations을 통해 200번째에서 평균이 변하였고 한 번의 변화가 있었음을 알 수 있습니다. 시각화는 plot(time, m1, 'l')에서 그려진 그래프 위에 평균값을 빨간색 선으로 나타낸 것입니다.
분산의 변화량이 발생하는 시점
- cpt.var(data, method = '', penalty = '', ...): 분산의 변화량이 발생하는 시점에 관한 내용을 객체 형태로 반환
- method에 설정할 수 있는 값으로는 AMOC, PELT, BinSeg, SegNeigh 등
- AMOC defalut값으로 변화점이 하나의 경우 사용되는 방법
- PELT는 정확하고 빠르지만 모든 분포에서 사용할 수 없음.
- BinSeg와 SegNeigh가 정확하고 빠름.
- method와 penalty값을 통해 상이한 결과 반환
- 자세한 내용은논문을 참고.
- method에 설정할 수 있는 값으로는 AMOC, PELT, BinSeg, SegNeigh 등
- cpts(cpt.var(data)): 분산의 변화량이 발생하는 시점을 벡터 형태로 반환
- param.est(cpt.var(data)): 분산의 변화량이 발생하는 시점에서 분산의 변화량 반환
# 난수 데이터 생성
v1 = c(rnorm(100,0,1),rnorm(100,0,2),rnorm(100,0,10),rnorm(100,0,9))
v1.man = cpt.var(v1,method = "PELT")
plot(v1.man)
cpts(v1.man) ## 100 200 param.est(v1.man)
정규분포를 이용하여 분산이 다른 4개의 난수 데이터를 생성하였음에도 분산의 변화하는 위치를 두 개만 추출된 이유는 첫번째 난수에서 분산은 1, 두번째 난수에서 분산은 2로 2배 차이가 나고 두번째 난수에서 분산은 2, 세번째 난수에서 분산은 10으로 5배 차이가 나는 것에 비해 세번째 난수의 분산과 네번째 난수의 분산의 차이는 적기 때문에 분산이 급격하게 변화하는 구간으로 탐지되지 않은 것입니다.

평균과 분산이 변하는 구간 파악
- cpt.meanvar(data)
rexp 함수는 지수분포를 이용하여 난수를 생성하는 함수입니다. 지수분포는 연속확률분포로 사람들이 미용실에 올 때 평균적으로 한 시간에 손님이 얼마나 올 것인가가 정해져있다면 사람들이 방문하는 시간 간격에 대한 분포를 지수 분포라고 합니다. cpt.meanvar함수는 분산이 변하는 것이 해당 분포안에서는 당연할 수 있기 때문에 보다 정확하게 평균과 분산의 변화량을 파악하기 위해 대략적으로 데이터가 어떤 분포를 사용하였는지 명시해주어야 합니다. 지수분포를 이용하였기 때문에 test.stat = 'Expotential'로 설정해줍니다.
method = 'BinSeg'방법을 통해 전체데이터를 구간화시켜 기존 데이터 대비 새로 들어온 데이터가 얼마나 다른지 통계를 test하여 p-value와 같은 값을 계산하여 극단성을 증명함으로써 앞의 데이터와는 다른 파라미터 값을 가지고 있는지를 찾아냅니다.
Q는 시각화를 통해 대략적인 변화점 개수를 파악하여 값을 입력하면 그 값과 비슷하게 찾아나가기 때문에 함수가 통계 test를 하는 시간을 줄여줄 수 있습니다.
penalty는 해당 데이터들이 이전 데이터들과 얼마 정도 다를때 어떻게 패널티를 줄것인가에 대한 방법입니다.
mv1 = c(rexp(50,rate=1),rexp(50,5),rexp(50,2),rexp(50,7))
mv1.binseg = cpt.meanvar(mv1,test.stat="Exponential",method="BinSeg",Q=10,penalty = "SIC")
# 변화시점 반환
cpts(mv1.binseg)
plot(mv1.binseg,cpt.width=3,cpt.col="blue")
지금까지 변화하는 시점을 파악해보았는데 이 값들 뿐만 아니라 파생변수를 이용하여 특질로 사용할 수 있습니다.
- 변화하는 시점
- 몇 번 변했는지
- 어떤 값에서 변화하였는지
- 변화한 시점의 간격의 평균, 최대값, 최소값 등의 요약값을 파생변수로 생성
- 변화가 있었던 시점 사이들의 간격을 파생변수로 생성 등등
# 변화의 개수
length(cpts(v1.man))
# 변화가 있었던 시점들 사이의 간격
diff(cpts(v1.man))
# 간격의 평균, 최대, 최소 모두 사용 가능
mean(diff(cpts(v1.man)))위 방법들을 계산하는 방법은 window방법을 이용하여 구간을 나누어 샘플링된 구간을 이동하며 표본에서 나온 통계치보다 극단적인 값이 나올 확률인 p-value를 구하여 0.05보다 낮은 값이 나오면 극단적인 경우로 판단하는 방식으로 변화하는 시점을 파악합니다.
미세하게 변화하는 시점 파악
공장에서 미세한 공정의 변화로 이상을 탐지하는 경우처럼미세한 변화를 파악하고 싶을 때는누적합을 이용하여 변화량을 탐지하는 방법을 이용하는 것이 효율적입니다. 이 방법은cusum(Cumulative Sum)패키지로 구현되어 있습니다.현재 시점까지 추정된 평균으로부터 에러를 구하고 미세한 변화량을 좀 더 잘 파악하기 위해 에러값을 누적하면서 평균에서는 보이지 않았던 변화를 파악할 수 있도록 합니다. 어느 시점부터 가파르게 증가하고 변하는지 파악하기 위해 평균으로부터 에러값을 누적해가며 추정되는 평균, 분산 대비 관리선 밖으로 넘어가며 미세한 변화량이 있었다는 것을 파악해냅니다.
병원의 의료시스템 성과 목표 달성 여부 데이터를 이용하여 실습해보겠습니다.
library(cusum)
data("cusum_example_data",package="cusum")
head(cusum_example_data)
cusum_example_p1 = cusum_example_data[cusum_example_data$year==2016,]
cusum_example_p2 = cusum_example_data[cusum_example_data$year==2017,]평균적으로 시스템에 얼마나 이상이 있는가
failure_probability = mean(cusum_example_p1$y)
- cusum_limit_sim(평균값, 데이터 개수, ...)을 이용하여 관리선 도출
- 급격한 변화(평균의 변화가 발생한 시점을 찾기)의 관리선 도출은 보통 데이터들의 산포하는 편차의 4sigma영역에서 도출됨.
- 전체 failure값이 누적되다가 6.4984 수치가 넘어가면 이상이 있다고 판단.
- n_simulation = 1000은 sampling과정을 1000번하여 관리선을 도출함.
n_patients = nrow(cusum_example_p1) # 데이터 개수
# 관리선 도출
cusum_limit = cusum_limit_sim(failure_probability, n_patients, odds_multiplier =2, n_simulation=1000,alpha = 0.05, seed = 2046)
cusum_limit # 이 값을 벗어나면 변화했다고 감지
[1] 6.4984
추정하고 있어야 할 값은 failure event 발생했던 횟수로 누적하고 있다가 어느 정도 발생한 횟수 기반으로 너무 많이 발생했다고 생각하고 검증
# 누적값과 상한값 표시하기
관리선 밖으로 값이 넘어가는지 확인하고 누적으로 이벤트 발생했던 값을 누적해서 횟수로 가지고 있다고 관리선을 넘어가면 이벤트가 발생했다고 알람을 줄 수 있음.
- reset: 변화가 발생한 지점에서 다시 초기화해서 변화발생을 다시 찾을 것인가?
- reset = TRUE: 변화가 발생하면 전의 분포는 지우고 새롭게 평균이 변화하는 것을 파악
- reset = FALSE: 변화를 추적할 때 전의 분포 기반해서 똑같은 기준을 적용하여 변화 파악
patient_outcomes = cusum_example_p2$y
cusum_cs = cusum(failure_probability, patient_outcomes, limit = cusum_limit,odds_multiplier = 2,reset = FALSE)
cusum_cs$signal # 변화가 없는 값은 0, 변화가 있는 값은 1로 나타남
plot(cusum_cs)


다음과 같이 변화가 언제발생했는지를 변수로 사용할 수 있습니다.(언제 1이 찍혔는가?) 관리선은 시뮬레이션 숫자와 신뢰구간을 정해서 도출해 낸 값으로 모든 데이터에서 동일한 기준점이 됩니다. 앞 분포 대비 관리선을 넘었다고 판단되면 미세한 변화가 발생했다고 도출됩니다.
'데이터 분석 > 비정형데이터분석' 카테고리의 다른 글
| [비정형 데이터] 06. 어떤 특징을 추출할 수 있을까? - 주파수 (0) | 2020.05.04 |
|---|---|
| [비정형 데이터] 05. 어떤 특징을 추출할 수 있을까?Peak (0) | 2020.04.30 |
| [비정형 데이터] 02. Tidyverse 패키지 다루기 (0) | 2020.04.29 |
| [비정형 데이터] 03. 어떤 특징을 추출할 수 있을까? - 통계적 특징 (0) | 2020.04.29 |
| [비정형 데이터] 01. 비정형 데이터 분석 (0) | 2020.04.29 |