2020. 4. 30. 16:40ㆍ데이터 분석/비정형데이터분석
저번 포스팅에 이어 신호처리를 위한 특질을 추출하내는 것입니다. 이번 포스팅은 peak특질을 추출하는 것입니다.
peak는 아래 그림과 같이 신호 데이터에서 위로 볼록 올라온 부분으로 peak 간 발생 간격, peak의 크기 등을 특질화하여 변수로 사용할 수 있습니다. peak는 pracma 패키지를 이용하여 구할 수 있습니다. pracma 패키지는 수치 분석 및 선형 대수, 수치 최적화, 미분 방정식, 시계열 등과 관련된 함수를 제공해주는 패키지로 기존 matlab기능이 R로 구현되어 있습니다.
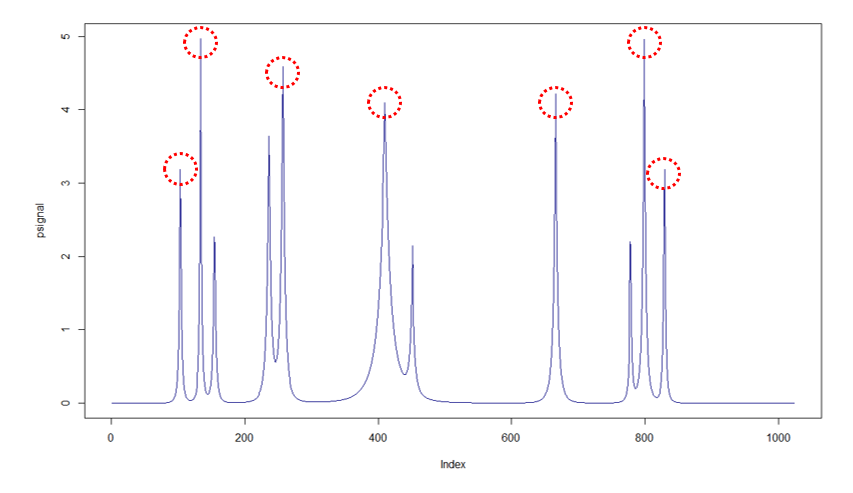
신호 데이터를 만들어 peak를 찾아보겠습니다.
library(pracma)
x = seq(0, 1, len = 1024)
pos = c(0.1, 0.13, 0.15, 0.23, 0.25, 0.40, 0.44, 0.65, 0.76, 0.78, 0.81)
hgt = c(4, 5, 3, 4, 5, 4.2, 2.1, 4.3, 3.1, 5.1, 4.2)
wdt = c(0.005, 0.005, 0.006, 0.01, 0.01, 0.03, 0.01, 0.01, 0.005, 0.008, 0.005)
psignal = numeric(length(x))
for (i in seq(along=pos)){
psignal = psignal+hgt[i]/(1+abs((x-pos[i])/wdt[i]))^4
}
plot(psignal,type='l',col="navy")
peak를 찾을 때는 몇 점 이상인 것들을 찾아낼 것인지에 대한 임계점을 설정합니다. 4 이상인 peak 중 상위 3개 peak만 추출해보도록 하겠습니다.
x = findpeaks(psignal, npeaks = 3, threshold = 4) # matlab기능을 구현해놓은 패키지이기 때문에 matrix형태로 결과가 반환
x
[,1] [,2] [,3] [,4]
[1,] 4.972146 134 118 144
[2,] 4.590829 257 246 306
[3,] 4.217588 666 589 733
첫번째 컬럼이 peak의 크기, 두번째 컬럼이 peak의 위치입니다. 세번째와 네번째는 잔피크들에 대한 값으로 첫번째 컬럼과 두번째 컬럼을 사용하여 특질을 추출해 낼 것입니다.
sortstr을 설정해주지 않으면 기본값이 FALSE이기 때문에 임계값이 4이상인 것들 중 peak의 위치가 먼저 나타나는 순으로 3개를 뽑아내지만 sortstr = TRUE를 설정하면 peak크기 순으로 정렬하여 상위 3개를 반환합니다.
x = findpeaks(psignal, npeaks = 3, threshold = 4, sortstr = TRUE) # matrix형태로 결과가 반환
x
[,1] [,2] [,3] [,4]
[1,] 4.972146 134 118 144
[2,] 4.960051 799 786 817
[3,] 4.590829 257 246 306
sortstr=TRUE 결과에서 주의해야할 점은 peak의 크기가 큰 순서대로 정렬되기 때문에 이후 peak가 발생한 지점 간의 간격을 구할 때 유의해야합니다..
points(x[,2],x[,1],pch=20,col="maroon")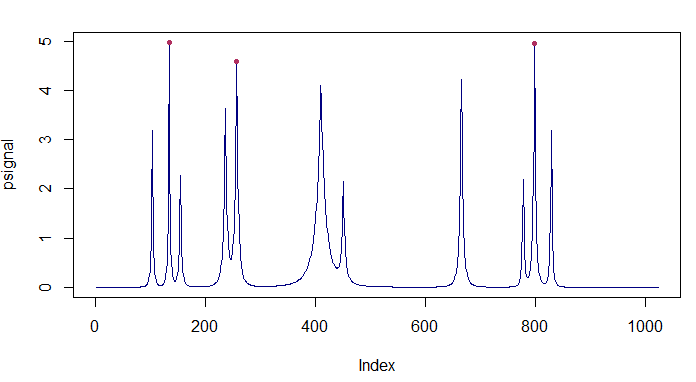
peak 시각화
x = findpeaks(psignal)
points(x[,2],x[,1],pch=20,col="maroon")
peak의 간격 시각화
# peak의 위치를 sort로 정렬
d = diff(sort(x[,2]))
hist(d)
peak 특질 추출
peak값 및 peak간격 그 값 자체 또는 기술 통계량을 적용한 값을 변수로 사용할 수 있습니다.
mean(x[,1])
sd(x[,1])
max(x[,1])
min(x[,1])mean(diff(sort(x[,2])))
median(diff(sort(x[,2]))) # 분포가 한 쪽으로 치우쳐져 있으면
std(diff(sort(x[,2]))) # 간격의 산포확인
diff(sort(x[,2]))) # 간격이 차이또는 peak가 얼마나 극단적인가를 나타내는 척도인 파고율로 특질을 추출할 수 있습니다.
파고율은 파형의 날카로움 정도의 비율 또는 최대값이 얼마나 영향을 주는지에 대한 비율(평균 신호 대비 얼마나 극단적인 값인가?)로 값이 1이면 peak가 없다는 것이고 6이면 크기가 매우 크다고 할 수 있습니다.

모든 피크에 대해서서도 구할 수 있고 가장 큰 peak에 대해서도 구할 수 있습니다.
주로 peak가 존재하지 않으므로 파고율 계산이 필요한 사각 구형파나 사인파로 이루어져 있는 정현파, 환경소음, 음성, 총소리 등에서 사용됩니다.
c = x[,1]/rms(psignal)
c = max(x[,1]/rms(psignal)) # 주로 사용하는 방법peak가 얼마나 극단적인가를 나타내는 척도는 PAPR(peak-to-average power ratio)도 있습니다 파고율에 제곱을 한 값으로 파고율과 동일하게 값이 1이면 peak가 없는 것입니다. 제곱을 취함으로써 비선형으로 만들어 이 값은 peak가 조금이라도 다르면 값의 변화를 진폭시키기 위한 값입니다.

심장의 전기자극에 따른 심장 근육의 수축이완 데이터를 이용하여 실습해보겠습니다. 해당 데이터는 전기 신호가 기록되어 있는 데이터입니다. peak가 일어나기 전 전조현상을 이용하여 peak를 추출하고자 합니다.
library(ade4) # 보건환경과 관련된 데이터들이 주로 존재
data(ecg)
plot(ecg)
심장에 이상이 있는 사람들은 정상인 사람들과 QRS파가 다르기 때문에 QRS파를 이용하여 정상과 그렇지 않은 경우를 판단할 수 있습니다.
데이터의 추세를 제거하기 위해 다항 함수를 이용하여 데이터의 추세를 나타낸 후 원본 데이터에서 추세 데이터를 뺍니다.
ployfit(인덱스,데이터,n차원 다항 함수의 n 값)과 polyval을 이용하여 polyfit의 데이터를 값으로 바꿔 추세 데이터를 생성합니다.
a =polyfit(1:length(ecg),ecg,6)
fit_y = polyval(a,1:length(ecg)) # polyfit의 데이터를 값으로 바꿈
원본데이터를 불러와서 원본데이터의 시각화와 추세 데이터의 시각화를 비교해봅니다.
library(ggplot2)
ecg_d = as.data.frame(ecg)
# ggplot(ecg_d, aes(1:length(ecg)))+geom_line(aes(y=ecg_d),colour="red")+geom_line(aes(y=fit_y),colour="green")
# n을 늘리면 더 잘 나타낼 수 있음.
# 추세가 제거된 값
ECG_data = ecg-fit_y
plot(ECG_data)
plot(1:length(ecg),ECG_data,"l")
# 심전도 신호에서 가장 두드러지게 반복 출현하는 피크인 QRS파 찾기
R = findpeaks(as.numeric(ECG_data),threshold = 0.5)
par(new=TRUE)
points(R[,2],R[,1],col="red")
S = findpeaks(as.numeric(-ECG_data),threshold = 0.5)
par(new=TRUE)
points(S[,2],-S[,1],col="blue")
Q peak는 잔신호들 때문에 제대로 추출이 안될 수 있기 때문에 잔신호들이 있을 때 필터링 하는 방법인 Savitzky-Golay filter를 이용하여 스무딩한 후 추출합니다. 21개 윈도우로 나누어 7차원 다항함수를 적용하여 스무딩해보도록 하겠습니다.
library(signal)
fit = sgolayfilt(ECG_data,7,21)
plot(1:length(ECG_data),as.vector(ECG_data),"l")
lines(as.vector(fit),col="red")
Q = findpeaks(-as.numeric(fit), threshold = 0.5)
plot(1:length(fit),fit,"l")
par(new=TRUE)
points(Q[,2],-Q[,1],col="red")
# 크기가 0.2에서 0.5 사이인 피크만 찾음
Q2 = Q[Q[,1]>0.1&Q[,1]<0.8,]
plot(1:length(fit),fit,"l")
par(new=TRUE)
points(Q[,2],-Q[,1],col="red")
'데이터 분석 > 비정형데이터분석' 카테고리의 다른 글
| [비정형 데이터] 07. 신호 데이터 스무딩하기 (0) | 2020.05.04 |
|---|---|
| [비정형 데이터] 06. 어떤 특징을 추출할 수 있을까? - 주파수 (0) | 2020.05.04 |
| [비정형 데이터] 04. 어떤 특징을 추출할 수 있을까? - 급격하게 변하는 시점 (0) | 2020.04.29 |
| [비정형 데이터] 02. Tidyverse 패키지 다루기 (0) | 2020.04.29 |
| [비정형 데이터] 03. 어떤 특징을 추출할 수 있을까? - 통계적 특징 (0) | 2020.04.29 |