[비정형 데이터] 07. 신호 데이터 스무딩하기
2020. 5. 4. 17:45ㆍ데이터 분석/비정형데이터분석
신호 데이터는 중요한 패턴에 대한 신호만 추출하고 싶은데 잔피크들이 너무 많을 때 스무딩을 이용하여 해결할 수 있습니다.
스무딩하는 방법에 대해 알아보겠습니다.
- Savitzky-Golay Filtering: data를 구간화해서 다차원함수에 적용하는 filtering 방법
- pracma 패키지의 savgol(data, 필터링 구간, 다항함수의 차수)함수
# 정현파 생성
ts = sin(2*pi*(1:1000)/200)
t1 = ts+rnorm(1000)/10
# 직접 그려보고 window값을 정해야함
t2 = savgol(t1,51) # pracma package
t3 = savgol(t1,101)
t4 = savgol(t1,5)
par(mfrow=c(2,2))
plot(1:1000,t1,col="grey", main='원데이터 정현파')
lines(1:1000,ts,col="blue")
plot(1:1000,t1,col="grey",main='window=51')
lines(1:1000,ts,col="blue")
lines(1:1000,t2,col="red")
plot(1:1000,t1,col="grey",main='window=101')
lines(1:1000,ts,col="blue")
lines(1:1000,t3,col="black")
plot(1:1000,t1,col="grey",main='window=5')
lines(1:1000,ts,col="blue")
lines(1:1000,t4,col="orange")

window값을 늘려가면서 비교해보면 window값이 커질수록 스무딩이 잘되는 것을 확인할 수 있습니다. 이때 window값에는 홀수값만 들어갈 수 있으니 주의하세요!
- median smoothing
- 아래 그래프와 같이 이상치가 심한 신호는 이상치에 민감하지 않게 스무딩하기 위해 중앙값을 이용한 스무딩 방법을 사용합니다.
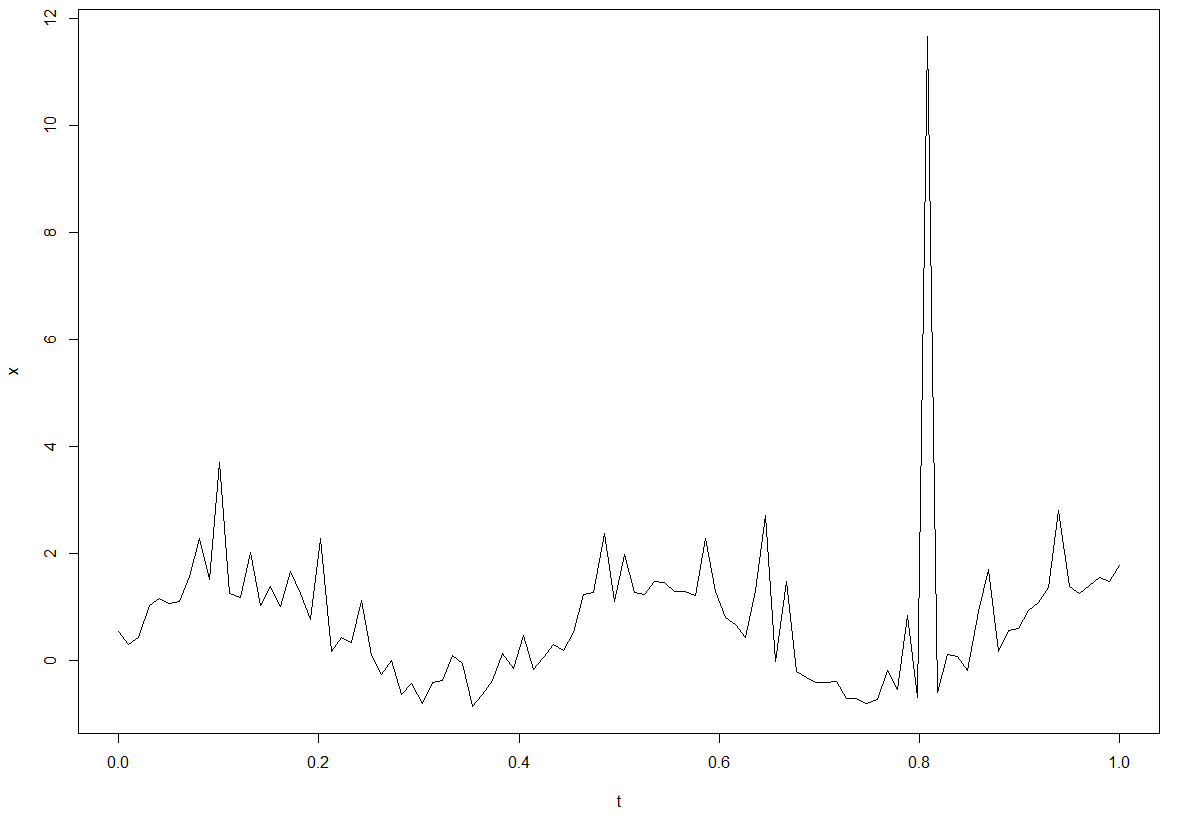
- medfilt1(x, n): 필터 설계와 필터링을 빠르게 연산
- MedianFilter(n): 필터 설계
- 필터 설계만 하는 함수이기 때문에 filter함수 내에서 사용해야함.
# 시간축 생성
t = seq(0,1,len=100)
x = sin(2*pi*t*2.3) + 0.25*rlnorm(length(t),0.5) # 이상치를 갖는 신호생성
plot(t,x,type="l")
lines(t, medfilt1(x),col="red",lwd=2)
lines(t, filter(MedianFilter(7),x),col='blue',lwd=2)
n의 개수가 넓을수록 스무딩이 잘되는 것을 확인할 수 있습니다.
- 이동평균 smoothing
- ARMA filter를 설계하는 방식
- autoregression(AR)모형: 현재 값의 p개의 과거 data를 이용하여 다음값 예측
- moving average(MA)모형: 과거 n개 값을 평균내어 현재값 측정
- Arma(MA 계수값, AR계수값)
- 원 데이터
- ARMA filter를 설계하는 방식
t = seq(0,1,len=100)
x = sin(2*pi*t*2.3) + 0.25*rlnorm(length(t),0.5) # 신호생성
plot(t,x,type="l")
filt = Arma(b=c(1,2,1)/3,a=c(1,1))
lines(t,signal::filter(filt,x), col="purple")
filt
- 샘플링 간격을 달리해서 스무딩
# 신호 생성
t = seq(0,1,len=100)
x= sin(2*pi*t*2.3)+0.25*rnorm(length(t))
plot(t,x,type='l')
# data간격을 0.01에서 0.1로 줄여서 추세만 따라가도록 만듦.
t1= seq(0,1, len =10)
x1= sin(2*pi*t1*2.3)+0.25*rnorm(length(t1))
lines(t1,x1,co='blue')

샘플링 간격을 줄여서 스무딩하면 스무딩 결과가 뚝뚝 끊기는 듯한 느낌을 받게됩니다. 이는 분포를 추정해서 스무딩하는 resample(data,p,q)함수로 해결할 수 있습니다. p/q의 비율을 구한 다음 해당 비율에 맞게 표현합니다.
아래 코드는 전체 데이터 중에 40%만 뽑아서 표현하겠다는 뜻입니다.
z = resample(x,4,10)
lines(seq(0,1,len=40),z,col='red')

파란선과 빨간선을 비교해보면 좀 더 부드럽게 스무딩된 것을 확인할 수 있습니다.
resample함수는 sink함수로 분포를 추정하여 값을 estimate하는 원리로 주변값들을 이용하여 fitting합니다. 데이터를 설명할 수 있는 확률 함수가 도출되면 해당 값들을 가상으로 만들어내어 연속데이터로 부드럽게 나타낼 수 있습니다.
임의로 샘플링 간격을 조정하는 것보다 주변값들을 통해 해당 위치를 설명할 수 있는 확률밀도함수를 생성하고 그에 기반한 그래프를 그리기 때문에 주변값을 고려한 대표값을 가져올 수 있습니다.
728x90
'데이터 분석 > 비정형데이터분석' 카테고리의 다른 글
| [비정형 데이터] 09. 신호데이터의 추세 제거하기 (0) | 2020.05.04 |
|---|---|
| [비정형 데이터] 08. 신호 데이터의 이상치 제거하기 (0) | 2020.05.04 |
| [비정형 데이터] 06. 어떤 특징을 추출할 수 있을까? - 주파수 (0) | 2020.05.04 |
| [비정형 데이터] 05. 어떤 특징을 추출할 수 있을까?Peak (0) | 2020.04.30 |
| [비정형 데이터] 04. 어떤 특징을 추출할 수 있을까? - 급격하게 변하는 시점 (0) | 2020.04.29 |