2020. 11. 13. 00:32ㆍML&DL
Wavenet은 음성 신호 Wave 자체를 모델링하여 음성을 생성하는 방법으로 2016년 구글 딥마인드에서 신경망을 이용하여 보다 자연스러운 TTS(Texts to Speech)를 개발한 것입니다. TTS란 텍스트를 음성으로 변환하는 것으로 오디오 북, 언어 교육 서비스, 외국어 더빙 등에 활용됩니다.
TTS
Wavenet이 나오기 전인 2015년 전통적인 TTS 모델들은 unit-selection speech synthesis 방법과 Statistical parameter speech synehesis 방법이 대표적이었습니다.
unit-selection speech synthesis 방법은 방대한 양의 DB가 있다고 가정하고 어떤 기준(음소 정보)에 따라 데이터를 불러온 후 작게 쪼갠 데이터를 concatenation하여 사용하는 것입니다. 즉, 잘게 쪼갠 데이터들인 unit 중 가장 적합한 데이터를 selection한 후 concatenation하여 음성을 만들어내는 것입니다. 이 방법은 실제 음성의 일부를 사용하기 때문에 높은 음성의 quality를 갖지만 완전히 새로운 DB에 기록하지 않고 음성 신호를 수정하는 것은 어렵고 음소 정보의 조합을 감당할 만큼 방대한 DB를 갖고 있어야한다는 단점이 있습니다.

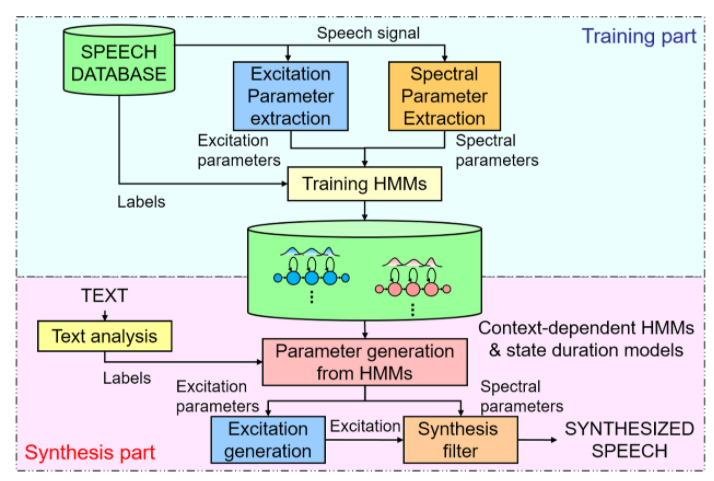
Statistical parameter speech synethesis 방법은 unit-selection speech synthesis의 대안 방법으로 통계적 방법으로 음성을 생성하는 방법입니다. text input이 text analysis를 통해 linguistic feature로 변환되고 변환된 feature를 뉴럴넷으로 구성된 Acoustic Model에 적용되어 음성 특징인 Acoustic feauture로 변환됩니다. Acoustic feauture가 Vocoder에 적용되어 통계 기반으로 모델링한 후 음성을 만들어내는 과정입니다. 이 방법은 Acoustic feauture를 조절하여 음성의 질을 높게 만들 수 있고 적은 양의 DB로 모델을 학습시킬 수 있지만 Vocoder 가 가지는 한계점으로 인해 결과물이 unit-selection speech synthesis보다 좋진 않습니다.
Wavenet
음성 신호를 위한 딥러닝 기반 generative 모델로 과거의 음성 샘플을 하나의 conditional information으로 주어서 현재 음성 샘플의 확률 분포를 통해 음성을 생성하는 방법입니다. TTS, voice conversion, music synthesis 등과 같이 waveform을 합성하는 것과 관련해서 사용됩니다. 음성 신호 자체를 한 번에 한 샘플씩 모델링하는 방법으로 보다 자연스러운 음성을 낼 수 있고 음성 신호 자체를 사용하기 때문에 음악을 포함한 모든 종류의 음성 신호를 모델링 할 수 있다는 장점이 있습니다.
waveform의 joint probability는 조건부 확률로 factorised해서 표현할 수 있기 때문에 이를 Stack of Convolution layer로 waveform의 joint probability로 모델링하는 방식입니다.
$$p(x) = \prod_{t=1}^{T}p(x_t | x_1, ... ,x_{t-1})$$
즉, CNN을 통한 조건부 확률 모델링으로 학습한 결과를 다시 input으로 사용하는 autoregressive 모델입니다.
Stack of Casual Convolution Layer
stack of casual convolution layer은 오직 과거의 파형 정보만 접근(casual 방식)할 수 있도록 casual convolution layer를 여러 겹 쌓습니다. CNN의 convolution layer에서 2X1 Filter를 사용하듯 input에 convolution을 취해서 어떤 값을 다음 layer 층으로 보냅니다. 이 과정을 다음 hidden layer에 값을 넘길 때마다 반복합니다.

waveform을 모델링할 때 문제점은 long term dependency입니다. 1초에 대한 샘플을 만들어낼 때 16000개의 과거 데이터를 이용해야합니다. 즉, 하나의 통계적인 특징을 제대로 모델링하기 위해 과거 수천개 떨어져있는 샘플들도 현재 샘플에 영향을 미칠 수 있습니다. 이를 해결하기 위해 과거 샘플들을 input으로 넣을 때 데이터를 얼만큼 볼 것인가로 사용되는 receptive Field를 얼마나 효율적으로 증가시키고 임베딩된 receptive Field 정보를 얼마나 효율적으로 인코딩 시켜서 최종적으로 적합한 확률분포를 만들어내는가에 대한 요지를 신경써야합니다.
하지만 stack of casual convolution layer는 receptive Field가 너무 좁다는 것입니다. 이를 해결하기 위해 나타난 방법이 dilated Casual Convolution방법입니다.
Receptive Field 수식: #layers + fileter length -1
Stack of Dilated Causal Convolution Layers
Receptive Field가 늘어난다는 것은 output을 계산할 때 사용하는 정보의 양이 많다는 것으로 성능이 좋아질 확률도 높지만 연산량이 증가한다는 단점도 있습니다. 하지만 Dialted방식은 receptive Field를 크게 만들어서 커버하는 영역은 늘리지만 연산량의 증가시키지 않는 효과적입니다. 아래 그림처럼 receptive Field를 크게 만들지만 중간중간 값은 0을 입력하여 연산량은 증가시키지 않습니다.

처음에는 일반적인 Convolution layer, 그 다음 layer는 일정 dilation만큼씩 간격을 두고 데이터를 convolution 한 다음 layer로 보냅니다. 적은 수의 층으로 더 많은 과거 정보를 이용하여 좀 더 효율적으로 output을 출력해낼 수 있습니다.
wavenet의 Stack of Dilated Causal Convolution Layers Receptive Field 수식: 2^#layers + 1

Softmax
논문에서 conditional distribution을 모델링할 때 softmax distribution을 사용하였습니다. 일반적으로 음성 신호는 16bit로 표현하기 때문에 65536개의 확률을 다뤄야합니다. 이 개수가 너무 많기 때문에 8bit, 즉 256개로도 좋은 성능을 낼 수 있도록 mu-law companding기법을 사용합니다. mu-law companding는 사람의 귀가 소리가 작을 때는 작은 변화에 민감하지만 소리가 클 때는 변화에 민감하지 않기 때문에 값이 작은 것은 작게 자르고 값이 큰 것은 크게 자르는 nonlinear한 양자화 방식입니다.
Gate Unit
wavenet은 Pixel CNN에서 사용된 gate activation unit을 사용하는데 이 게이트는 LSTM을 다룰 때 사용하는 gate개념과 동일하게 생각하시면 됩니다. convolution한 값에 gate unit을 통과시켜 값을 얼마나 통과시킬까를 결정하는 네트워크를 생성(Wg,k)하는 단계로 sigmoid를 activaion function으로 써서 0~1 값으로 나타낸 후 판단합니다.
gate activation unit: z=tanh(Wf,k∗x)⊙σ(Wg,k∗x)
⊙: element-wise 곱셈
σ(⋅): 시그모이드 함수
W: 학습 가능한 convolution filter
: filter
: gate
: layer의 번호
즉, gate 연산은 매 층마다 input값에 filter와 gate에 대한 convolution을 각각 구한 뒤 element-wise 곱을 구하는 것입니다. wavenet이 conditional한 information으로 사용되면 conditional한 information을 임베딩 시켜주기 위해 사용되기도합니다.
Residual & skip connection
한 layer 마다 residual 블록으로 이루어져있습니다. 한 residual 블록은 Dilated Causal Convolution Layers, gate activation, residual, skip connection으로 이루어져 있습니다. Residual, skip connection은 층이 늘어나면서 딥해지는 모델의 학습 속도를 높이고 안정적으로 수렴할 수 있도록 하기 위해 사용합니다.
input이 입력되고 Casual Convolution 후 receptive Field를 증가시켜주기 위해 Dilated Causal Convolution이 적용되고 gate unit을 거친 후 residual에 대한 1x1 convolution과 skip connection에 대한 1x1 convolution을 따로 구한 것으로 보입니다. 이 과정은 layer의 개수만큼 반복된 후 합쳐집니다.

Condition Wavenets
Wavenet은 특정한 특성을 나타내도록 조건 h를 줄 수 있습니다. 예를 들어 어떤 사람의 특정 목소리를 만든다거나 텍스트 정보를 주어 텍스트를 읽도록 만드는 등의 조건을 줄 수 있습니다. 조건을 주는 방법에는 모든 timestep에 동일한 조건을 주는 Global conditioning방법과 TTS 모델의 linguistic features를 추출할 때처럼 조건이 timestep에 따라 변하는 경우 사용하는 Local conditioning방법이 있습니다.

Global Conditioning 수식에서 condition을 나타내는 latent vector h에 V를 linear projection을 합니다. 이때 V는 학습가능하도로고 만들어 linear projection합니다. condition을 줄 때 add로 주거나 concatenate를 하는데 add는 더하기 연산 concatenate는 채널 방향으로 두 텐서를 연결하는 연산입니다. 이 논문에서 Vf,k*h는 1X1 convolution을 나타내기 때문에 상관없는 것 같습니다.
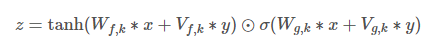
Local conditioning방법은 timestep에 맞춰서 신호가 변하도록 샘플을 upsampling 한 후 1x1 convolution한 후 conditiion을 줍니다.
출처
[1] 03. 음성합성이 뭐야? 컴퓨터가 음성을 만든다
[2] [논문] WaveNet - A Generative Model for Raw Audio
[3] deepmind.com/blog/article/wavenet-generative-model-raw-audio
[4] 논문
[5] Generative Model-Based Text-to-Speech Synthesis
'ML&DL' 카테고리의 다른 글
| [DL] 06. 새로운 데이터를 생성하는 법, GAN? (0) | 2020.12.08 |
|---|---|
| [DL] 05. 데이터를 압축하고 생성하는 AutoEncoder? (0) | 2020.12.08 |
| [ML] 수식과 함께 SVM 이론 파헤치기 (0) | 2020.11.12 |
| [ML] 하나의 class만 학습시켜서 불균형 데이터 예측하기 (0) | 2020.11.12 |
| [DL] 02. CNN 구조 이해하기 (0) | 2020.10.27 |