2020. 10. 27. 15:27ㆍML&DL
이번에는 이미지 분류에 주로 사용되는 CNN에 대해 알아보겠습니다.
CNN은 이미지 분류, 이미지에 잡음 제거, 글자 인식(OCR) 등에 주로 사용됩니다.
FNN으로 이미지를 분류하기에는 한계가 존재합니다. 픽셀 값이 많고 컬러가 들어가는 복잡한 구조들은 최소 3개의 층으로 구성되어야하기 때문에 데이터의 사이즈가 커지면서 층이 깊어지고 파라미터들이 증가하게 됩니다. 데이터 샘플 수가 적은데 파라미터 수가 많아지면 주어진 데이터에 대해 오버피팅이 일어날 수 있습니다. 그렇다면 데이터의 샘플 수가 많으면 되지 않나? 라고 생각하실 수 있으실텐데요. 데이터의 샘플 수가 많아지면 여러기법을 적용할 수 있어서 좋긴 하지만 메모리를 많이 먹고 오래거립니다. 또한 FNN은 전체적인 특성을 고려할 때는 좋지만 이미지와 같이 부분적으로 특성을 고려하는 것이 더 좋을 때는 CNN을 사용하는 것이 좋습니다.

CNN은 뽑아내고 싶은 특징(Filter)과 얼마만큼 데이터가 닮아있는지를 보는 것으로 부분적으로 특성을 추출하는 이미지에 적합한 것입니다. convolution 연산을 통해 지역적인 특성을 고려하고 동일한 weight를 sharing을 하기 때문에 파라미터 수가 감소하여 오버피팅이 발생할 확률이 낮아진다는 장점이 존재합니다.
전체적인 동작방식은 다음과 같습니다.
[Feature extraction]
1. input 데이터에 filter와 convolution 연산을 통해 feature map 출력
- 다양한 filter를 사용하여 특징을 추출할 수 있음.
2. overfitting을 방지하기 위해 pooling 적용(선택사항)
3. feature 특성이 적절하게 추출될 때까지 1, 2 번 과정 반복
[Classification]
4. 1차원 데이터로 flatten
- 분류 작업일 때 출력값이 1차원 벡터이기 때문에 flatten
5. one hot vector size로 맞춘 후 최종적으로 분류
CNN은 convolution 연산 후 pooling layer를 통해 특징이 추출되는 부분과 Fully Connected Layer를 구성하고 마지막 출력층에 softmax를 적용하는 분류 부분으로 구성됩니다.
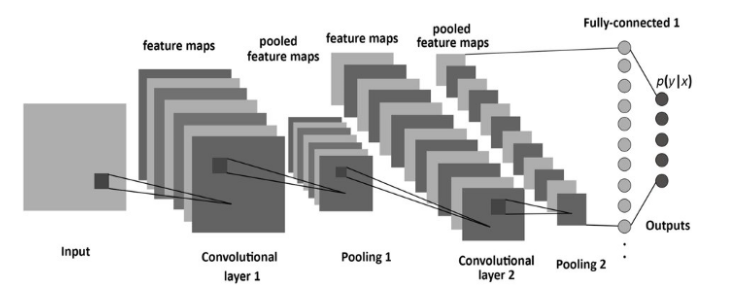
구체적으로 용어와 동작과정에 대해 살펴보겠습니다.
Convolution
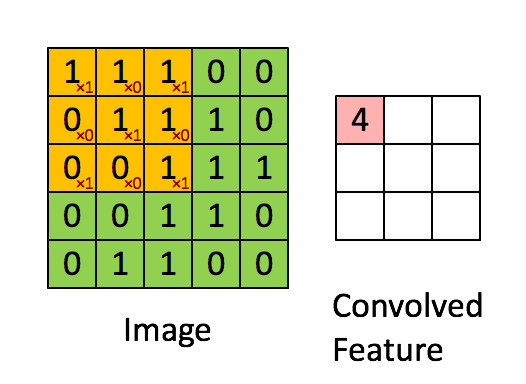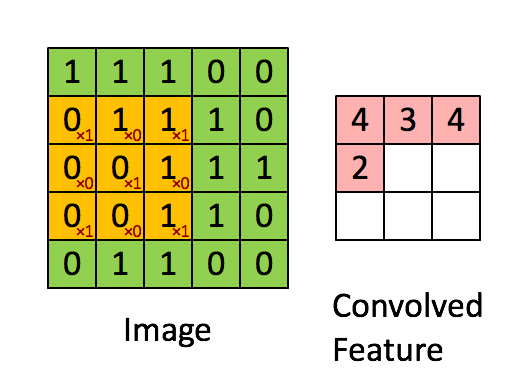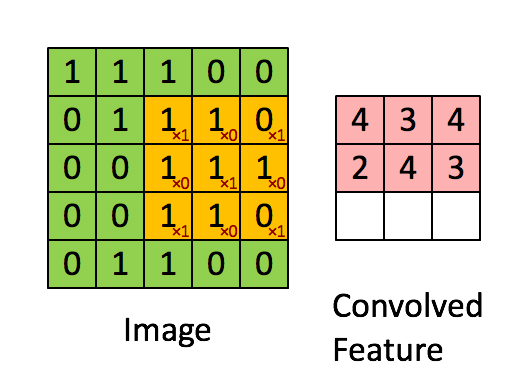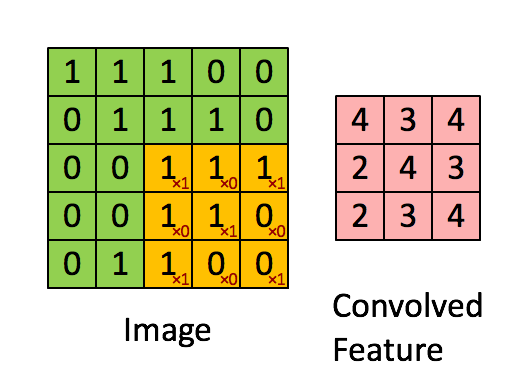
convolution은 합성곱으로 입력데이터보다 차원이 작은 Filter와 입력 데이터에 합성곱 연산을 수행하는 것을의미합니다. 이때 지역적인 특성을 추출하기 위해 filter의 weight값을 동일하게 shift시키며 연산합니다.
Channel
흑백이미지는 1개 채널, 컬러 이미지는 3개의 채널로 이루어져 있습니다. 하나의 채널은 하나의 2차원 배열로 생각하면 되고 1개의 입력 채널에는 1개의 필터 채널이 필요합니다. 즉, 입력 데이터의 채널 수와 필터의 채널 수가 일치해야합니다.
Filter
필터는 특성을 추출해내기 위한 것으로 kernel이라고도 합니다. 일반적으로 정사각 행렬로 정의되고 여러 개의 필터를 동시에 사용할 수 있습니다. 각 필터마다 해당하는 특징을 추출해서 여러개의 Feature들을 동시에 사용할 수 있도록합니다. 필터는 지정된 간격으로 순회하며 채널별로 합성곱을 하고 모든 채널의 합성곱의 합을 Feature map으로 만듭니다.
Stride
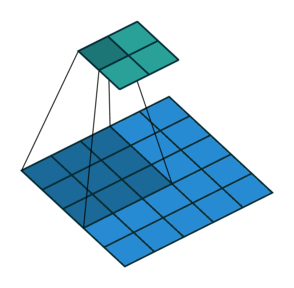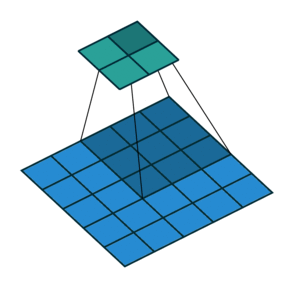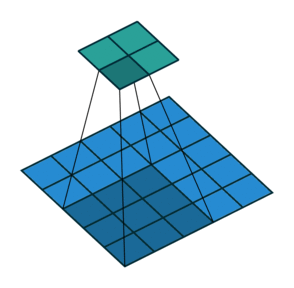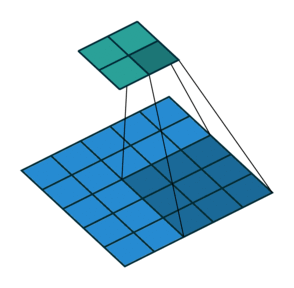
stride는 필터가 지정된 간격으로 순회할 때 간격을 의미합니다. 즉, 필터를 몇 칸씩 shift 시킬 것인가? 를 의미합니다.
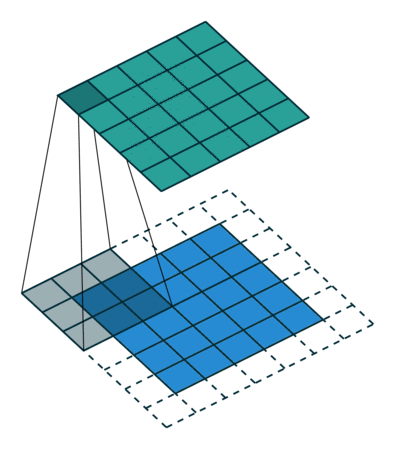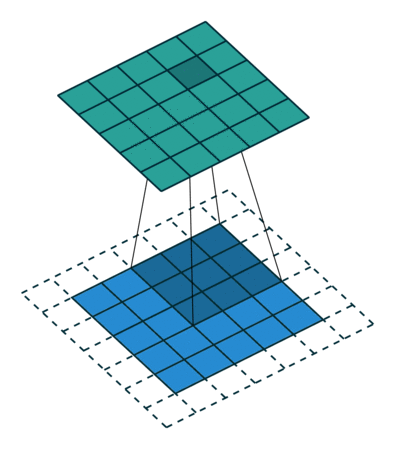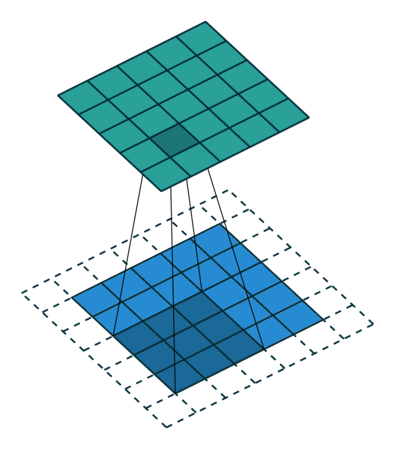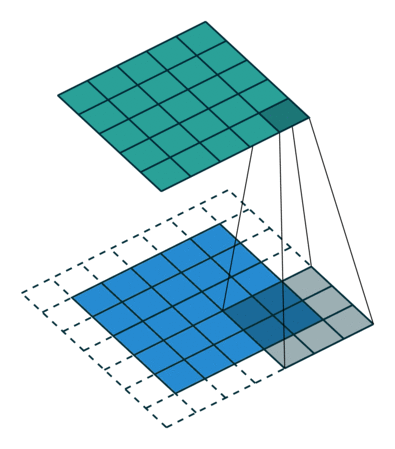
아래 그림은 stride가 2일 때 filter가 적용되는 그림입니다. (출처)
Padding
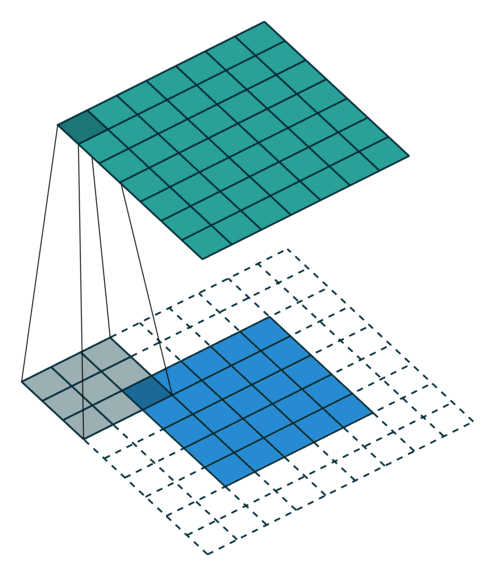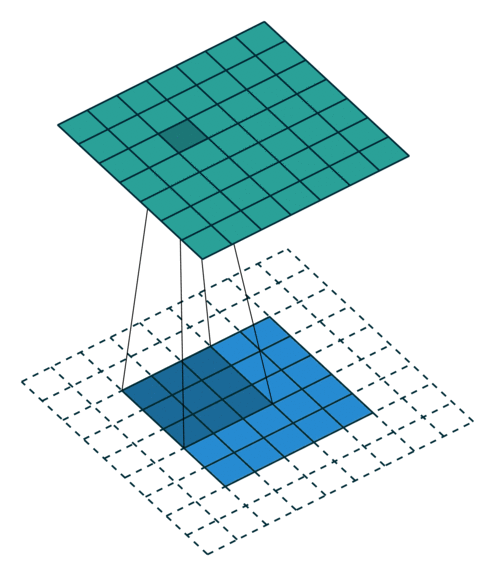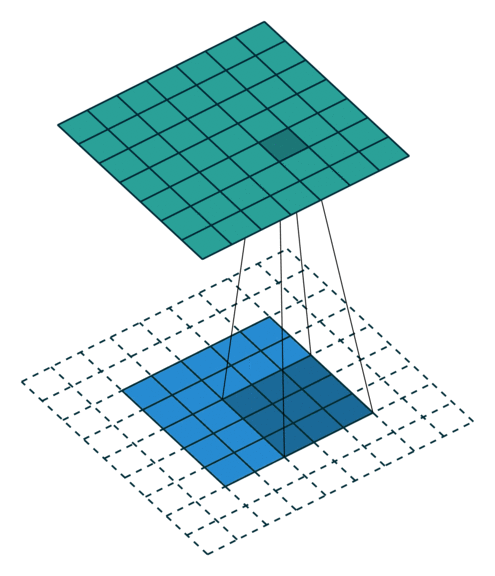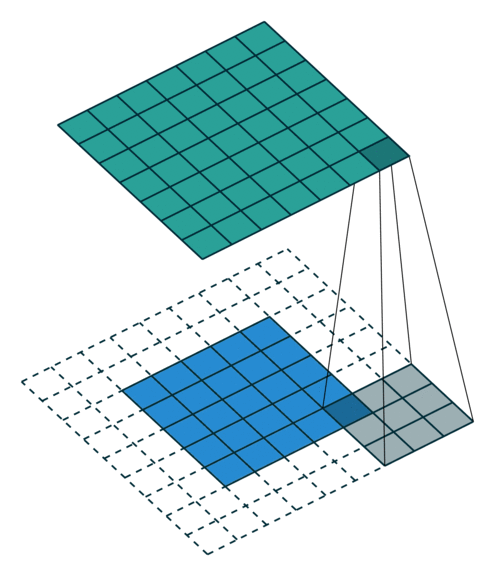
filter size만큼 shift하면 filter size는 data의 입력 사이즈보다 작기 때문에 feature map의 크기가 입력 data의 size보다 작아집니다. 특징이 제대로 추출되지 않았는데 차원이 적어지면 특징이 유실될 수 있기 때문에 데이터의 외곽에 특정 값을 채워넣는 padding을 사용하여 방지합니다. 보통 패딩 값으로 0을 채워넣어 사이즈만 늘리는 역할을 할 수 있도록 합니다. 아래 그림은 외곽에 padding을 적용한 것입니다. (출처)
- Full padding: 의미가 있는 한도 내에 가장 크게 padding하는 방식
- 처음에 겹치는 한 픽셀만 너무 강조가 될 수 있는데 이 부분이 특성을 추출하기에 필요한 부분인지 아닌지 고려를 하고 적용해야함.
- Same padding: 입출력 사이즈를 동일하게 맞추는 방식
- Valid padding: padding을 하지 않는 방식
- 겹치는 구간이 많기 때문에 image 내에서 각 pixell 값들이 고르게 학습되지 않을 수 있음.
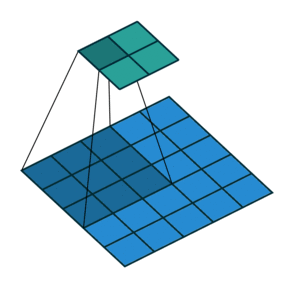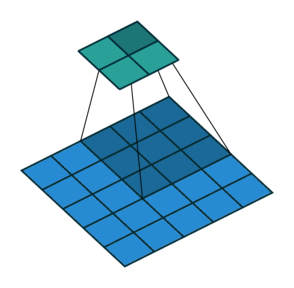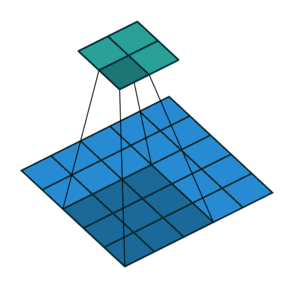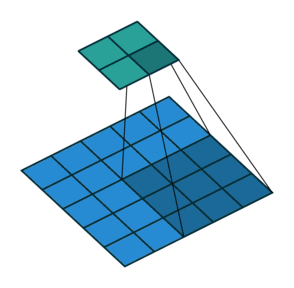
Pooling
pooling layer는 convolution layer의 출력 데이터인 feature map을 입력으로 받아서 feature map의 사이즈를 줄이거나 특정 데이터를 강조하기 위해 사용됩니다. pixel 한 칸씩 옆으로 이동하며 convolution을 진행하면 중간중간 겹치는 부분들이 존재합니다. 불필요한 값들에 대해서는 특성을 뽑아내는 문제를 해결할 수 있습니다. pooling 방법에는 최대값을 뽑아내는 Max pooling, 평균값을 뽑아내는 Average pooling 등이 존재합니다. 일반적으로 pooling 크기와 stride 크기를 같은 크기로 설정하여 모든 원소가 한 번씩 처리 되도록 설정하지만 pooling layer 에 입력된 데이터 전체에 최대값, 평균 등을 사용하여 값을 출력하는 Global Max Pooling, Global Average Pooling이 존재합니다. 다음과 같이 특징을 추출할 때 어떤 특징을 뽑고 싶은지에 따라 pooling 사이즈를 조절할 수 있고 꼭 정방행렬이 아니어도 됩니다.

보통 convolution layer와 pooling layer를 하나의 layer로 표현합니다. (pooling은 선택적)
Dropout
CNN은 차원을 줄여나가기 위해 추출하고자 하는 차원은 대체로 입력보다 작기 때문에 일부 쓸모없는 데이터들이 존재합니다. dropout은 이러한 데이터들을 제거함으로써 오버피팅을 방지하기 위해 사용합니다. convolution layer의 마지막에 사용가능하지만 pooling에서 dropout의 효과를 내래 수 있기 때문에 잘 사용하지 않지만 랜덤하게 노드들을 띄어넘고 싶을 때 dropout을 사용할 수 있습니다. 대부분의 경우 dropout을 사용하면 train에서는 안좋은 성능이 나타나지만 test에서는 좋은 성능을 나타냅니다. 그 이유는 학습할 때 중간중간 생략하며 학습했기 때문입니다.
Backpropagation
아래 그림은 CNN의 forward propagation을 표현한 그림입니다. convolution 연산을 일렬로 핀 그림으로 같은 색끼리는 weight sharing이 일어납니다.
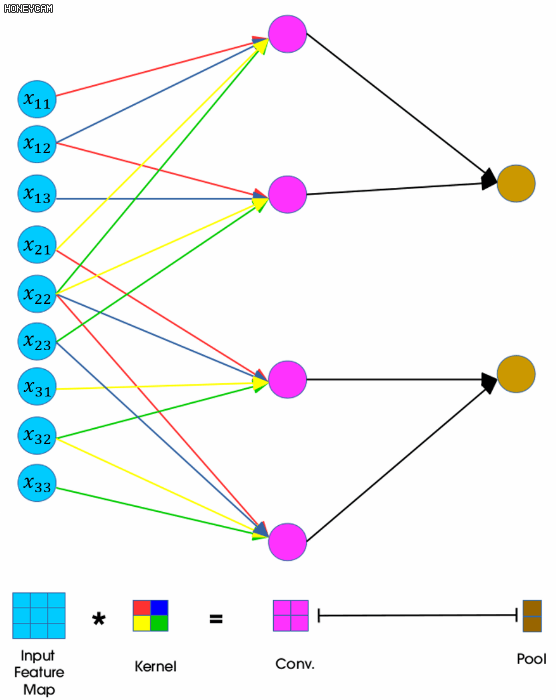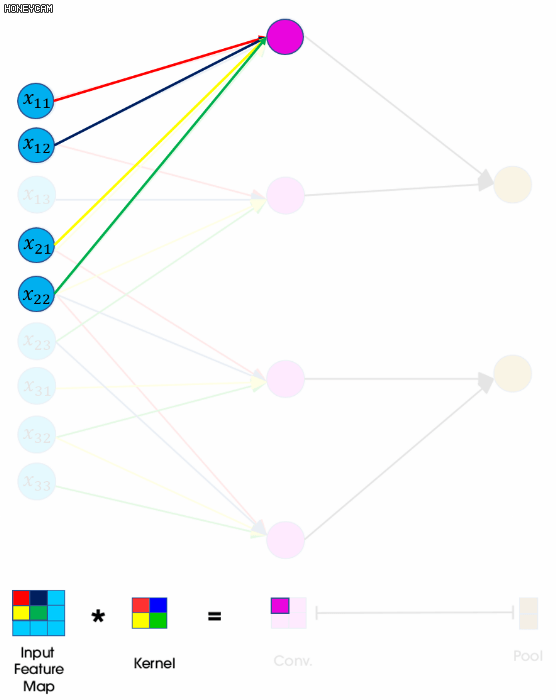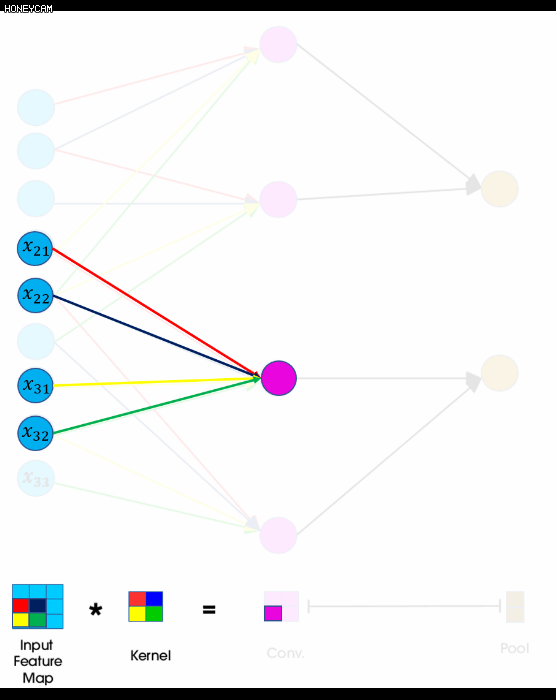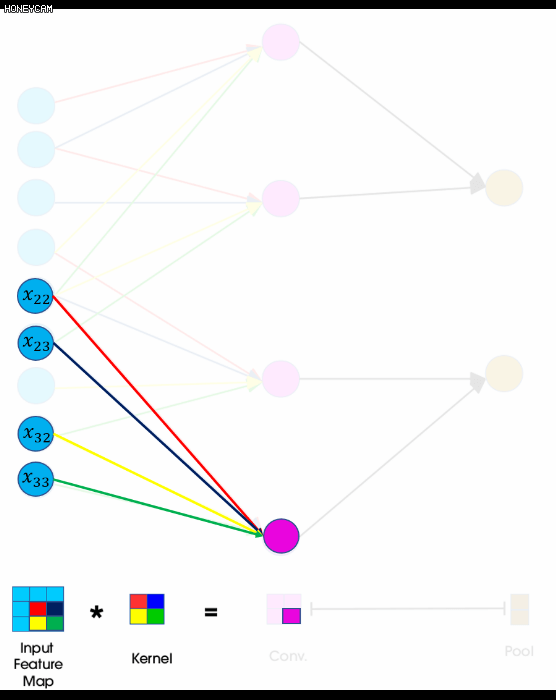
FNN과 달리 각각 미분해서 기울기를 구하지 않고 forward 방식에서처럼 역방향으로 필터 요소의 순서를 정반대로 바꾼 필터와 convolution연산을 shift시키며 진행합니다. weight sharing으로 인해 좀 더 편하게 계산하기 위해 matrix로 계산합니다.

동작방식
1. 필터를 rotation한 후 correlation을 통해 feature map 출력
2. feature map이 출력의 마지막 값일 때, loss값을 구하고 gradient값을 구한다.
3. rotation과 correlation을 합쳐서 convolution이라 하는데 convolution 연산을 통해 중간 layer 값 도출
4. loss를 w로 미분한 기울기 도출
참고
What are Max pooling, Average Pooling, Global Max Pooling and Global Average Pooling?
'ML&DL' 카테고리의 다른 글
| [DL] 05. 데이터를 압축하고 생성하는 AutoEncoder? (0) | 2020.12.08 |
|---|---|
| [DL] 음성 신호 모델링하는 방법, Wavenet 알아보기 - A Generative Model for Raw Audio (0) | 2020.11.13 |
| [ML] 수식과 함께 SVM 이론 파헤치기 (0) | 2020.11.12 |
| [ML] 하나의 class만 학습시켜서 불균형 데이터 예측하기 (0) | 2020.11.12 |
| [DL] 01. 딥러닝의 기초 개념 이해하기 (0) | 2020.06.20 |