2020. 12. 9. 22:17ㆍ데이터 분석/통계분석
이번 글은 주성분 분석(Principal Component Analysis)에 대한 설명입니다. 주성분 분석은 차원을 축소하는 기법 중 하나로 잠재 공간을 만들어내거나 다중공선성이 발견했을 때 해결할 수도 있고, 데이터 압축, 노이즈 제거, 영상 인식 등 다양하게 사용됩니다.
순서
1. 차원 축소?
2. 주성분 분석
3. 주성분 분석 실습
1. 차원 축소
관측 데이터를 잘 설명할 수 있는 잠재 공간은 어떻게 발견할 수 있을까요? 데이터의 모든 Feature(독립 변수)들이 종속 변수를 잘 설명할 수 있을까요? "차원의 저주" 라는 말 들어보셨나요? 차원의 저주는 차원이 늘어날수록 설명력이 낮아진다는 것으로 독립 변수들이 많으면 모델링에 필요한 학습 집합의 크기가 커지고 노이즈의 특징들까지 포함되어 모델을 구출하는데 독이 된다는 것을 말합니다. 또한 차원이 늘어났기 때문에 학습 속도가 느려지죠. 이처럼 모든 Feature들이 데이터를 설명하는데 필요하지 않을 수 있고 가지고 있습니다. 또는 Feature들 중 몇몇 Feature들의 조합으로 표현이 가능하면 다른 Feature들이 불필요해지기도 합니다. 그래서 관측 데이터를 잘 설명할 수 있는 잠재 공간(latent space)은 실제 관측 공간(observation space) 보다 작을 수 있습니다. 잠재 공간을 차원 축소를 통해 발견될 수 있고, 차원 축소는 잠재공간을 발견하는 것 외에도 데이터를 압축하거나 노이즈를 제거하는데도 사용됩니다.
데이터의 차원을 줄이는 방법은 특징 선택(Feature Selection)과 특징 추출(Feature Extraction) 두 가지가 있습니다.
Feature Selection은 Feature들을 제거하면서 필요한 Feature들만 남기는 것이고 Feature Extraction은 Feature들의 조합으로 새로운 Feature를 생성하는 것을 말합니다. 그 예로 Auto-Encoder, 주성분 분석 등이 있습니다.
2. 주성분 분석
주성분 분석은 독립 변수들 간의 영향력이 있는 경우 결합하는 형태로 가상의 핵심 성분을 뽑아서 새로운 변수를 생성하는 것을 말합니다. 주성분 분석의 목적은 정보 손실을 최소화하면서 서로 상관관계가 있는 변수들 사이의 복잡한 구조를 이해하기 쉽게 설명하고자 하는데 있습니다. 비지도 학습 방법으로 각각의 독립 변수들에 새로운 주성분을 생성합니다. 이 주성분을 변수로 사용하여 서로 독립적인 새로운 변수가 됩니다. 주성분 분석을 통해 만들어진 변수들은 서로 독립적이기 때문에 다중공선성이 발생했을 때 해결하기 위해 사용하기도 합니다. 다중공선성이란 독립 변수들 간 강한 상관관계가 존재하는 경우 다중공선성이 발생했다고 말합니다. 다중 공선성은 분산팽창인수인 VIF(Variance Inflation Factor)를 활용하여 5이상이면 존재할 가능성이 있다고 판단하고 보통 10이상이면 심각한 다중공선성이 있다고 판단합니다. 다중공선성이 발생하면 다중공선성을 일으키는 변수 중 종속변수와의 상관관계가 낮은 변수를 제거하거나 제거 시 결정계수가 유지되는 변수를 제거하여 해결할 수 있습니다. 또한 주성분 분석이나 Ridge Regression을 이용하여 회귀분석에 적용할 수도 있습니다.
주성분 분석은 데이터들의 분포 특성을 가장 잘 나타낼 수 있는 벡터를 찾는 것이기 때문에 가장 처음 주성분은 데이터의 분산(변동)이 가장 큰 방향의 벡터, 두 번째 주성분은 첫번째 주성분에 직교하면서 데이터들의 분산이 가장 큰 벡터를 찾는 것입니다.


주성분 분석은 변수들 간 단위 차이가 클수록 표준화하고 사용해야합니다. 분석하는 절차를 코드를 이용하여 실습해보겠습니다.
3. 주성분 분석 실습
R의 HSAUR패키지의 heptathlon 데이터로 실습해보겠습니다.
heptathlon데이터는 서울 올림픽 7종 경기 데이터입니다. 200m~800m 달리기는 작을수록 좋은 점수, 높이뛰기와 포환던지기는 클수록 좋은 점수입니다. 이처럼 변수의 좋은 점수를 갖는 방향이 다르다면 종합 점수를 계산하는 것이기 때문에 방향을 바꿔줘야합니다.
library(HSAUR)
heptathlon
# 작은 값일수록 좋은 점수이기 때문에 최대값에서 값을 빼줌,
heptathlon$hurdles <- max(heptathlon$hurdles) - heptathlon$hurdles
heptathlon$run200m <- max(heptathlon$run200m) - heptathlon$run200m
heptathlon$run800m <- max(heptathlon$run800m) - heptathlon$run800m
종합 점수 변수는 제외하고 결측치와 상관관계를 확인합니다.
heptathlon$score = NULL
colSums(is.na(heptathlon)) # 결측치 모두 0
pairs.panels(heptathlon)
상관관계 결과 높은 상관관계를 띄는 변수들이 많습니다. 이런 경우는 회귀모델에 적용 시 다중공선성이 의심되는 상황이죠.
데이터에 표준화를 적용하고 공분산 행렬을 사용하여 주성분 분석을 실시합니다.
heptathlon_pca = prcomp(heptathlon, center = TRUE, scale. = TRUE)
heptathlon_pca
summary(heptathlon_pca)

주성분의 수는 변수의 수만큼 출력되고 Standard deviation에 제곱한 값은 분산으로 고유값, Proportion Variance는 분산의 비율로 기여율, Cumulative Proportion은 누적 기여율입니다. 보통 누적 기여율이 80% 이상이 되는 주성분까지 사용하여 분석에 적용합니다. 위의 경우 PC1, PC2를 사용합니다. 또는 screeplot을 이용하여 주성분 수를 결정할 수 있습니다. screeplot은 x축이 i번째 주성분, y축이 고유값입니다.
screeplot(heptathlon_pca,type='line',pch=19,main='Scree Plot of pca')
그래프의 기울기가 완만해지는 i번째 주성분전까지 사용합니다. 누적 기여율과 같이 제2 주성분까지 사용하겠다고 결정하면 됩니다.

다음은 주성분 점수, 고유벡터, 원데이터의 평균, 주성분 점수의 표준편차에 대해 알아보겠습니다.
heptathlon_pca$x # 주성분점수

heptathlon_pca$rotation # 고유벡터

고유벡터를 기준으로 식을 세우면 다음과 같습니다.

제 1주성분을 기준으로 고유벡터의 절댓값이 longjump가 가장 크기 때문에 좌표를 그렸을 때 -방향의 영향력이 가장 크다고 할 수 있습니다. 이를 이용하여 주성분 점수에 -값 중 가장 큰 값을 가지는 것이 종합 점수를 따졌을 때 가장 큰 점수를 갖는 변수다라고 말합니다. 제 1 주성분에 가장 영향을 가장 많이 미치는 변수는 멀리뛰기, 110m 허들 변수이지만 창던지기 변수를 제외하곤 대부분 비슷하게 영향을 끼치는 것으로 보이기 때문에 공식점수 변수, 제 2주성분에 가장 영향을 많이 미치는 변수는 창던지기 변수로 다른 값들에 비해 매우 현저하게 값이 높기 때문에 창던지기 변수라고 이름을 가정하여 변수로 사용할 수도 있습니다.
heptathlon_pca$center # 원데이터의 평균

heptathlon_pca$sdev # 주성분점수의 표준편차

다음은 Biplot을 이용하여 주성분 그래프를 해석하겠습니다. Biplot은 첫번째 주성분이 x축, 두번째 주성분이 y축으로 고유값과 고유벡터 모두를 고려하여 원래 변수와 주성분 간의 관계를 그래프로 표현한 것입니다. 그래프에서 화살표는 원래 변수와 주성분 변수의 상관계수를 뜻하고 주성분 벡터와 평행할수록 큰 주성분에 크게 영향을 미칩니다. 즉 화살표 벡터의 길이가 원래 변수의 분산을 표현하고 길수록 분산이 큰 것입니다.
biplot(heptathlon_pca,cex=0.7,col=c('red','blue'),main='Biplot')
highjump, hurdles, run800m, longjump가 가까운 곳에 위치하며 비슷한 벡터 방향을 갖고 있고 Run200m, shot이 가까운 위치, 비슷한 벡터 방향을 갖고 있습니다. Javelin은 다른 변수들과 다른 벡터 방향을 갖고 있습니다. run200m와 shot 모두 비슷하게 좋은 값을 가지는 선수는 Joyner-Kersee(USA), javelin을 가장 잘하는 선수는 Choubenkova(URS)입니다.
pairs.panels(round(heptathlon_pca$x,2))
주성분 분석 후 상관계수를 확인해보면 모두 0으로 서로 독립인 형태가 된다는 것도 확인합니다.
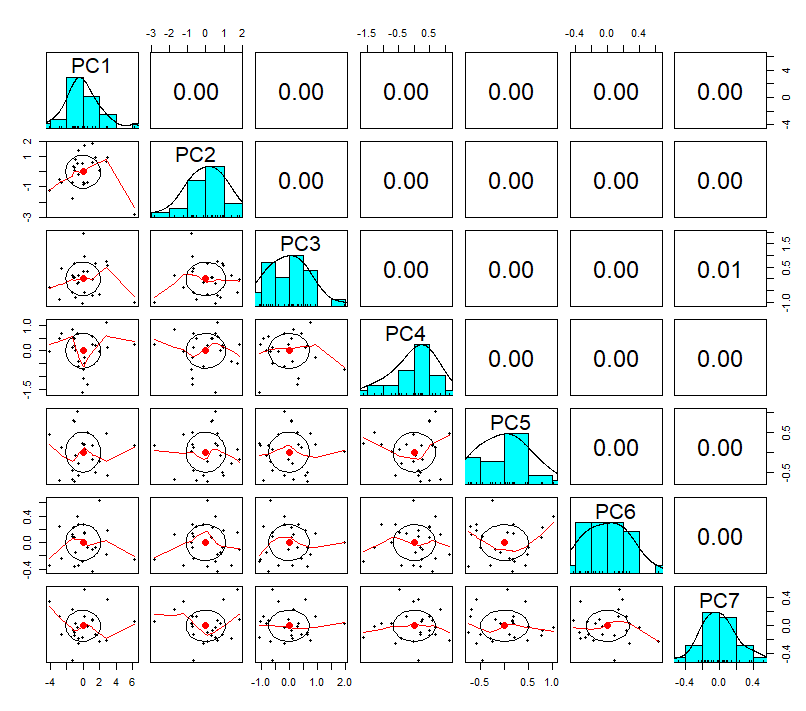
참고
[1] 1. 차원축소(주성분 분석)
'데이터 분석 > 통계분석' 카테고리의 다른 글
| [통계분석] 05. 범주형 변수, 어떤 검정을 할 수 있을까? (0) | 2021.02.02 |
|---|---|
| [통계분석] 04. 연속형 변수, 어떻게 가설 검정을 할까? (0) | 2021.01.29 |
| [통계분석] 03. 가설 검정의 기초를 이해하자. (0) | 2021.01.29 |
| [통계분석] 02.모수를 왜 추정하고, 어떻게 추정하는거지? (0) | 2021.01.29 |
| [통계분석] 01. 확률분포는 머신러닝에서 어떻게 사용될까? (1) | 2021.01.29 |