2020. 6. 20. 18:17ㆍML&DL
이번 포스팅은 딥러닝에 대해 다뤄보고자 합니다.
딥러닝 개요
딥러닝은 4차 산업혁명의 핵심기술로 부각되고 있고 AI(Artificail intelligence)라는 용어로 자주 쓰이고 있습니다. 딥러닝은 1980년대에 붐을 일으켰지만 하드웨어가 모델을 따라가지 못하여 잠깐 주춤했고 최근 컴퓨터의 성능이 좋아지면서 복잡한 모델을 다룰 수 있는 환경이 마련되었습니다.
딥러닝이 나온 배경은 사람이 어떤 신경 세포들로부터 자극을 받아 대뇌로 전달한 후 사람이 인지하는 과정을 묘사하여 모델로 만든 것입니다. 정확한 메커니즘이 구현된 것은 아니지만 신경 세포들이 감각을 모으고 축삭돌기로 전달되면서 인지할 수 있는 신호로 바뀐다는 개념을 컴퓨터에 적용한 것이 인공신경망 모델입니다.
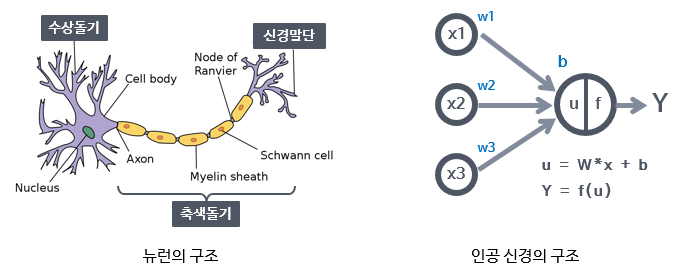
어떤 input data가 들어오면 input 들을 모아 다른 정보로 변환하고 층을 쌓으며 가공하는 과정을 거쳐 output을 출력합니다. 예를 들어 핸드폰 센서 데이터가 input이라면 이 데이터들을 추상화하는 과정을 거쳐 뛰고 있는 데이터인지, 계단을 내려가는 데이터인지와 같이 사람이 인지할 수 있는 데이터로 변환할 수 있습니다.
인공지능은 사람이 공부하는 것과 같습니다. 사람도 학습해서 지식을 얻습니다. 교과서를 통해 학습하는데 교과서에 기록되어 있는 것을 데이터라고 합니다. 사람도 데이터를 갖고 공부를 합니다. 사람은 교과서를 많이 보면 시험을 잘 볼 수 있습니다. 이처럼 기계도 input데이터를 계속 학습하며 스스로 패턴을 찾아 output을 도출해냅니다. 인공지능의 역할은 input데이터가 있으면 학습할 수 있는 메커니즘이 존재하고 학습을 통해 결과를 도출해냅니다. 이때 메커니즘으로 머신러닝이 있고 그 중 하나가 딥러닝입니다. 기계학습 모델들은 input데이터를 받아 패턴을 발견한 후 일반화할 수 있는 결과를 반환합니다. Machine learning은 input 데이터에 과외 선생님이 있어서 어떤 특성을 뽑으면 좋은지와 같은 feature 선택 과정을 필요로 하지만 deep learning 은 feature engineering없이도 스스로 학습하여 결과를 도출해낼 수 있다는 것이 차이점입니다.
딥러닝 모델의 동작 과정
input data들이 들어오면 weight값을 이용하여 가중화 형태로 만들어냅니다. 이를 층마다 적용하여 결과로 반환합니다. 이때 가중합을 구할 때 weight값들이 적절한 값을 갖고 있어야 output값이 제대로 출력됩니다.
y = wx+b
w: 가중치
b: bias
인공신경망의 목표: x, y가 주어졌을 때 w,b를 찾아내는 것
하지만 weight값을 첨부터 적절한 값을 맞출 수 없기 때문에 역전파 알고리즘을 이용하여 try&error 방식을 반복하며(반복적인 에러교정) 답을 찾아냅니다.
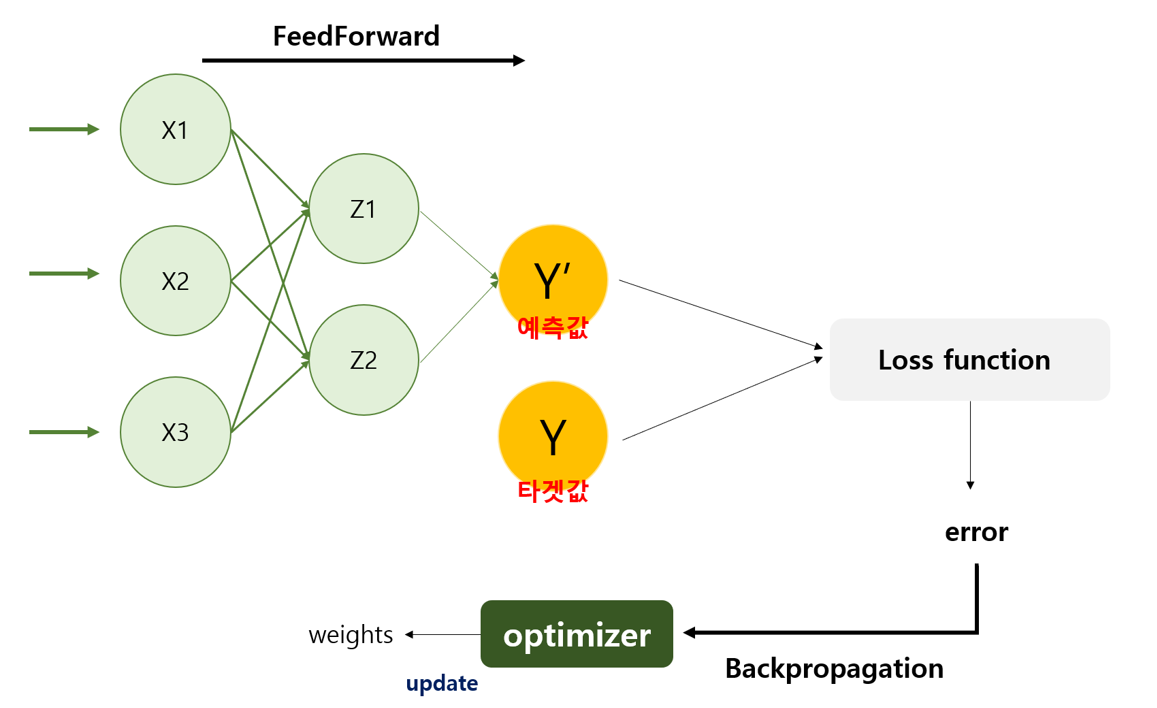
Optimizer
optimizer에는 여러 종류가 있는데 그 중 가장 간단한 알고리즘은 정답과 알고리즘이 예측한 값의 차이인 loss(cost) 값을 줄이는 방향으로 weight의 기울기(gradient)를 조정해나가는 알고리즘으로 Gradient Descent라고 합니다.
신경망에서 구한 답과 실제 답의 차이가 점점 멀어지면 안되기 때문에 차이에 제곱을 구하여 미분을 통해 기울기를 타고 내려가며 최솟값이 되도록 만드는 알고리즘입니다.
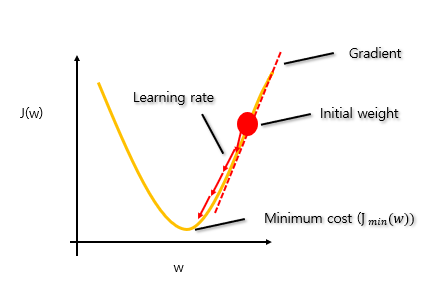
weight 가 업데이트되는 수식을 간단하게 살펴보면 다음과 같이 나타낼 수 있습니다.
weight update = 에러를 낮추는 방향(descent) * learning rate * 현 지점의 기울기(gradient)
weight의 기울기가 음수면 w값을 키우고, 양수면 w값을 작게만들면서 기울기가 0에 가까워지도록 만듭니다. 이때 learning rate가 너무 크면 overshooting이 되고, learning rate가 너무 작으면 local minimum에 빠지게 됩니다. learning rate 값을 설정할 때는 초기에 큰 값을 부여해서 빨리 찾도록 하고 iteration이 증가함(성능이 좋아짐)에 따라 폭을 줄이기 때문에 작은 값으로 바꿔가며 조절하는 것이 좋습니다.

하지만 gradient descent는 오래 걸리기 때문에 일부 batch를 검토하여 속도를 개선한 Stochastic Gradient Descent 알고리즘, 전에 움직였던 방향과 양을 기억하며 이동하는 Momentum 등 여러가지 종류의 발전된 optimizer들이 존재합니다.
활성화 함수
weighted sum을 구하다보면 값이 이상한 값으로 발산하는 경우가 있는데 이는 activation function(활성화 함수)을 이용하여 막을 수 있습니다. cost function을 최소화한다는 것은 미분을 해서 값을 update한다는 것이므로 활성화함수는 미분이 가능한 함수여야 합니다.
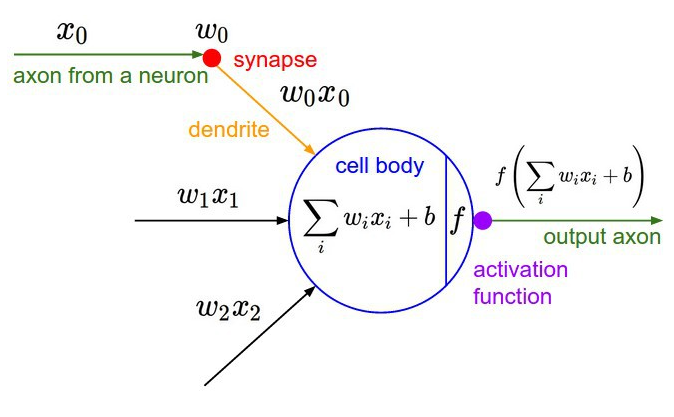
활성화 함수는 몇 가지를 알아보겠습니다.
1. sigmoid: 0~1 사이의 값만 가질 수 있도록 하는 비선형 함수 σ(x)=1/(1+e−x)
- 확률로 표현이 가능하기 때문에 odd ratio라고 불리고 이 함수에 log를 취해서 logit function, z = log(y/1-y)
- 분류에서는 이 값이 1보다 커지면 class1, 0보다 작으면 class 0 이라고 하고 log를 씌우는 이유는 값이 극단적으로 나오는 것을 방지하기 위해
- 단점: sigmoid는 매우 큰 값을 가지면 거의 1, 매우 작은 값을 가지면 거의 0에 도달하기 때문에 미분함수에 대해 일정값 이상 커질 시 미분 값이 소실되는 gradient vanishinig 문제가 있고 중심값이 0이 아니기 때문에 최적화 과정이 느림.
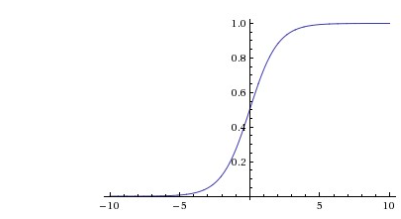
2. tanh: sigmoid의 중심값을 0으로 옮겨 -1~1사이의 값을 가질 수 있도록 하는 비선형 함수 tanh(x)=2σ(2x)−1
- 중심값을 0으로 옮겨 sigmoid보다 빨라졌지만 아직 gradient vanishing 문제가 존재.
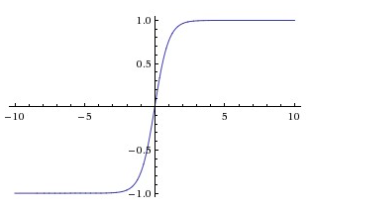
3. ReLu: 값이 0보다 작거나 같으면 0, 크면 해당 값을 가지는 함수 f(x)=max(0,x)
- sigmoid, tanh보다 빠르다.
- 연산비용이 크지 않고 매우 간단하게 구현 가능
- 단점: x<0인 값들은 기울기가 0이기 때문에 뉴런이 죽을 수 있음.
활성화 함수는 어떤 함수를 사용하느냐에 따라 출력값이 달라질 수 있기 때문에 적절한 활성화 함수를 사용하는 것이 중요합니다. 보통 같은 layer에 같은 활성화 함수를 사용하고 다른 layer에 대해서는 다른 활성화 함수를 사용할 수 있습니다.
하지만 다중 분류할 때 사용되는 softmax 활성화 함수는 주로 마지막 출력 layer에서 사용하고 그 전 layer에서는 다른 활성화 함수를 사용하는 것이 성능면에서 더 좋은 결과를 가져올 수 있습니다.
마무리
딥러닝이 획기적이었던 이유는 추가적인 계층들을 이용하여 선형으로 구할 수 없는 비선형패턴까지 발견할 수 있어서 각광을 받게되었습니다. 무작정 층을 많이 쌓고 뉴런을 많이 쌓는 것이 좋은 것만은 아닙니다. 신경망 구조를 만들 때 그림과 같이 적절한 뉴런의 개수와 hidden layer의 개수로 모델을 만들어야합니다. 간단한 모델부터 시작해서 모델을 복잡하게 만들어나가는 것이 좋습니다. feature도 많으면 많을수록 무조건 좋은 것이 아닙니다. 오히려 복잡도가 증가하기 때문에 중요한 feature는 가중치를 주는 등의 노력을 필요로 합니다.
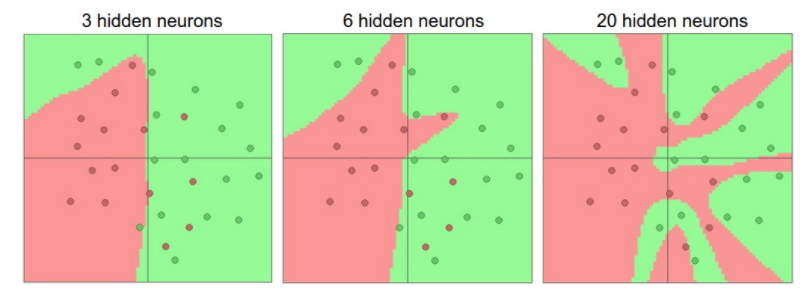
또한 딥러닝은 feature들을 자동으로 추출해서 패턴을 발견하기 때문에 데이터의 특성을 몰라도 할 수 있는 것일 뿐 몰라도 되는 건 아닙니다. 데이터의 특성을 반영해서 전처리를 하고 모델을 만들 때 반영하면 더 좋은 성능을 도출해낼 수 있을 수도 있기 때문에 특성을 파악하는 것은 의미있는 일입니다.
딥러닝 모델은 층을 쌓아나가면서 더 좋은 결과를 도출하는 알고리즘인 DNN, 이 모델이 발전하여 CNN, RNN 등의 모델들이 나왔습니다. CNN은 이미지 데이터 분류에 주로 사용하는 방법이고 RNN은 시계열 데이터를 다룰 때 주로 사용하는 방법입니다. 물론 DNN이나 CNN을 이용하여 시계열 데이터를 다룰 수도 있습니다. CNN은 1D CNN을 이용하여 시계열 데이터를 다루는데 이에 관한 내용들은 추후 다루도록 하겠습니다.
참고
www.slideshare.net/yongho/ss-79607172
cs231n.github.io/neural-networks-1/
subinium.github.io/Keras-1/
'ML&DL' 카테고리의 다른 글
| [DL] 05. 데이터를 압축하고 생성하는 AutoEncoder? (0) | 2020.12.08 |
|---|---|
| [DL] 음성 신호 모델링하는 방법, Wavenet 알아보기 - A Generative Model for Raw Audio (0) | 2020.11.13 |
| [ML] 수식과 함께 SVM 이론 파헤치기 (0) | 2020.11.12 |
| [ML] 하나의 class만 학습시켜서 불균형 데이터 예측하기 (0) | 2020.11.12 |
| [DL] 02. CNN 구조 이해하기 (0) | 2020.10.27 |