2021. 1. 30. 23:21ㆍ개인/프로젝트
데이터 아키텍처 수업을 들으면서 한 프로젝트입니다. 데이터 수집, 전처리, 모델링, 웹에 표현하는 과정을 담은 프로젝트를 진행하였습니다.
순서
1. 문제 정의
2. 데이터 수집 및 저장
3. 데이터 전처리
4. 데이터 모델링
5. 데이터 적재
6. PHP를 이용하여 웹에 표현하기
1. 문제 정의
대부분 국민 청원 게시판을 이용해보셨을 것입니다. 국민 청원 게시판은 언론의 자유를 존중하며 자유롭게 글을 게시할 수 있지만 아래의 청원 게시글 모음처럼 동일한 내용의 게시글이 중복되어 게시되어 있기 때문에 청원 동의 수가 분산되는 문제점이 존재합니다. 이러한 문제점으로 인해 사람들은 어느 청원에 동의를 하는 것이 좋은 걸까? 어는 청원에 동의해야 답변을 받을 수 있는 걸까? 하는 고민들이 발생합니다.

20만 명이라는 적지 않은 사람들의 동의를 30일 내로 받아야 하는데 정말 중요하게 응답되어야 하는 게시글들이 중복 청원으로 인해 무시될 수도 있습니다. 이것은 엄연한 국민 청원 게시판의 문제점이라고 생각합니다.
그래서 중복 청원을 집약한 웹을 구성하려고 합니다.
저의 메인 기능은 중복 청원이지만 타겟은 청원에 동의하고 싶은데 분산된 청원으로 인해 곤란한 사람, 국민 청원 게시판의 글들을 한눈에 보고 어떤 것들이 최근 문제가 되고 있는지 보고 싶은 사람입니다. 보다 많은 사람들이 국가의 이슈에 관심을 가졌으면 하는 마음입니다.

웹에 표현하는 과정은 아래와 같습니다. 유사한 청원들을 워드클라우드로 나타내어 한눈에 주제를 확인하고 중복되는 글을 모아놓은 페이지로 이동할 수 있도록 만들 것입니다. 중복되는 글을 모아놓은 페이지에서는 긴 글을 요약해서 볼 수 있도록 할 것입니다. 이는 국민 청원 방문자들이 국민의 의견에 더 많은 관심을 가졌으면 하는 바람입니다. 긴 글을 읽기 힘들어하는 사람들을 위해 요약하여 보여주는 것이 도움이 될 것이라 생각했습니다. 워드클라우드 생성, 유사도 검정, 텍스트 요약이 제 프로젝트의 주요 과정입니다.

2. 데이터 수집 및 저장
국민 청원 게시판을 크롤링하여 데이터를 수집합니다. 국민 청원 게시판의 robots.txt를 확인했을 때 따로 명시된 내용은 없었습니다. 하지만 로봇의 접근을 막는 것 같습니다. 크롤링 시 중간중간 쉬는 시간을 걸어줘야했습니다.

전체 목록의 글들을 수집했습니다. 국민 청원 게시판은 www1.president.go.kr/petitions/596187 처럼 뒤에 596187과 같은 게시글 고유번호가 있습니다. URL에 Parameter를 붙여서 전송하는 GET 방식으로 서버를 연결합니다. 저는 이 번호를 이용하여 데이터를 수집하였습니다. 타겟은 청원에 동의하려는 사람들이기 때문에 청원 진행 중인 게시글 중 게시글 고유번호가 가장 낮은 번호부터 크롤링하도록 하였습니다. (게시글 고유번호는 시간의 흐름에 따라 +1이 되므로)
데이터를 수집할 때 주의해야할 점은 관리자에 의해 비공개된 청원이 있다는 것입니다. 수집하려는 HTML 요소 값들과 다르기 때문에 이 부분은 수집되지 않도록 코드를 작성해야 합니다.
국민 청원 게시판 글에서 청원 고유 번호, 청원 시작 날짜, 끝나는 날짜, 제목, 내용, 청원 동의 수, 카테고리, 청원 진행 상태, 게시글 링크를 수집했습니다.

php를 이용하여 MySQL을 접속한 후 DB와 TABLE을 생성하였습니다. 데이터는 계속 업데이트되어야하기 때문에 작업 스케줄러를 이용하여 매일 데이터가 수집되고 적재될 수 있도록 하였습니다. 매일 수집된 데이터를 추가로 적재할 때 Primary Key를 기준으로 청원 진행 상태와 청원 동의 수가 매번 업데이트되어야 하기 때문에 ON DUPLICATE KEY UPDATE 함수를 통해 데이터를 업데이트하여 적재하도록 만들었습니다.

3. 데이터 전처리 및 분석
3.1. 유사도 검정
먼저 청원 상태가 청원 진행 중인 데이터만 추출해서 게시글의 정규표현식 및 불필요한 글자를 제거합니다. 청원 글이 꽤 많기 때문에 일정 청원 동의 수 이상인 청원 게시글만 뽑아서 사용하였습니다. Okt 형태소 분석기를 이용하여 형태소를 분석하였습니다. Twitter 형태소 분석기가 Okt 형태소 분석기입니다. Hannanum, Mecab이나 Kkma와 같이 자세하게 분류될 필요는 없었고 Komoran은 분석을 못해서 Okt 형태소 분석기를 사용하였습니다.

TF-IDF를 활용하여 벡터화 한 후 cosine similarity를 이용하여 유사도를 추출하였습니다. TF-IDF는 문서 내 특정 언어가 해당 문서 내에서 얼마나 중요한가를 나타내는 수치입니다. 그중 유사한 문서가 5개 이상 있는 경우만 추출하여 화면에 나타낼 수 있도록 만들었습니다. 유사도 검정 후 유사하다고 판단한 그룹을 기준응로 확인했을 때 category는 모두 동일했을까요?
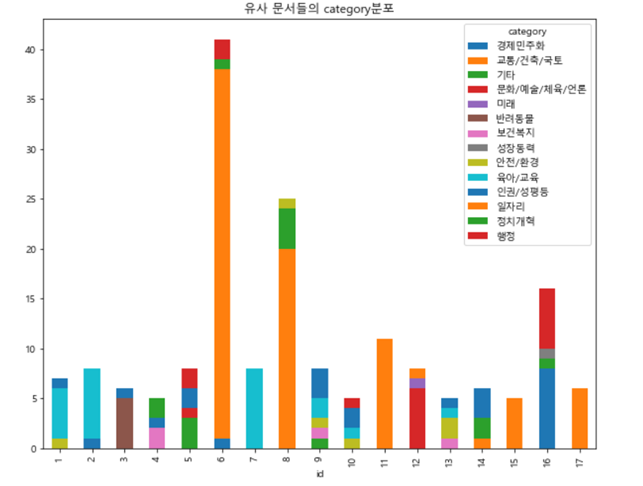
그렇지 않았습니다. 그래서 저는 따로 카테고리를 나누는 기능은 두지 않아야겠다고 판단했습니다.
3.2. 텍스트 요약
유사도 검정 시 Okt 형태소 분석기를 적용하기 전 데이터에 gensim 알고리즘을 이용하여 게시글을 요약했습니다. gensim 알고리즘은 본문이 특정 개수 문장 이하일 경우 결과가 반환되지 않습니다. 이런 경우는 요약하지 않고 본문에서 앞 3문장만 보여줄 수 있도록 했습니다.
3.3. 워드클라우드 생성
텍스트 요약과 마찬가지로 Okt 형태소 분석기를 적용하기 전 데이터에서 "그것, 저것, 안녕하십니까, 또한, 대해, 당시"와 같은 불용어들을 제거한 후 Okt 형태소 분석기를 적용하였습니다. 적용 후 명사만 추출하여 php로 워드 클라우드를 나타내기 위해 데이터를 DB에 적재하였습니다.
4. 데이터 적재
유사한 글들을 올리기 위한 테이블, 워드클라우드를 나타내기 위한 테이블, 요약한 게시글을 담을 테이블 3개를 만들어서 데이터를 적재하였습니다.
5. PHP를 이용하여 웹페이지 구현
메인 페이지입니다. 메인 페이지는 유사한 글들을 모아 워드클라우드를 통해 한눈에 볼 수 있도록 "청원 한눈에 모아 보기"와 관심있게 본 청원 게시글을 동의 수를 하나로 집중시키기 위해 해당 게시글의 고유 번호를 입력하면 유사한 글들을 찾아주는 "코드 번호로 유사 글 검색" 기능이 있습니다. 아래는 코드 번호로 유사한 글을 검색하는 방법을 모르실 수도 있기 때문에 설명을 추가하였습니다.
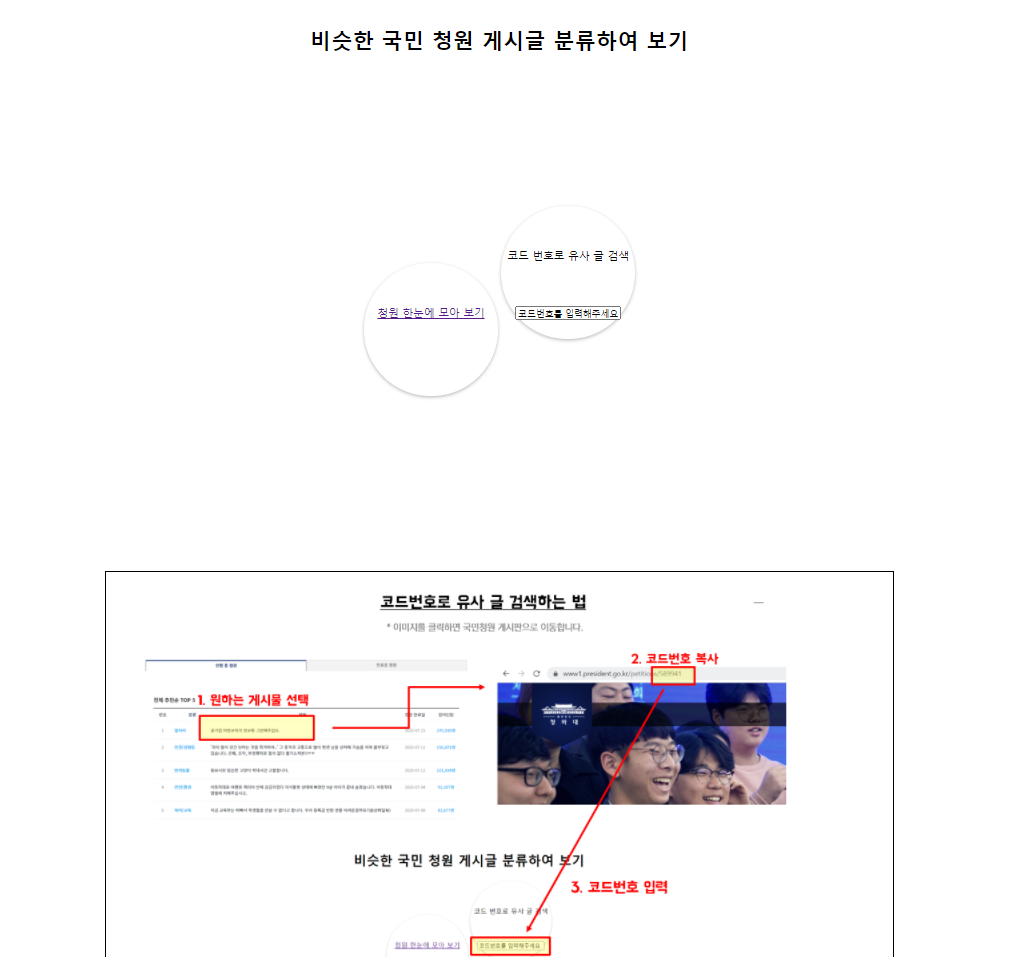
청원 한눈에 모아 보기를 클릭하면 워드클라우드들이 나옵니다. 관심 있는 워드클라우드를 클릭하여 유사한 글들을 확인할 수 있습니다.

유사한 글들은 청원 동의 수가 많은 순서대로 배치되고 관련 청원의 제목, 동의 현황을 따로 볼 수 있도록 만들었습니다. 마우스 커서를 막대그래프 위에 갖다 대면 해당 게시글의 요약된 글로 게시글을 미리 읽을 수 있습니다. 요약된 글을 읽고 관심이 생겼다면 해당 막대그래프 또는 아래 표의 청원 링크를 클릭하여 청원 동의 페이지로 이동합니다. 이 페이지에서 다른 워드클라우드를 클릭하여 다른 글들도 보고 싶다면 "전체 목록 보기"를 클릭하고 메인 페이지에서 코드 번호로 글을 검색하고 싶다면 메인 페이지로 가기를 클릭합니다.

코드 번호로 유사한 글들의 모음을 볼 때는 빈칸에 코드 번호를 입력하여 "유사한 청원 모아보기" 페이지로 이동할 수 있는데 만약 유사한 글이 없다면 아래와 같이 경고창이 뜨고 확인을 클릭하면 입력한 코드 번호의 게시글로 이동하고 취소를 클릭하면 다시 메인페이지로 돌아갑니다.

어떤가요? 분산된 청원으로 인해 곤란한 사람들에게 도움이 될 수 있는 프로젝트를 기획했다고 생각하는데 제가 생각한 타겟도 그렇게 생각했으면 좋겠습니다. 국민 청원을 통해 많은 사람들이 문제 삼고 있는 국가적 이슈를 확인하고 싶어 관심을 가지다 너무 많은 글들로 인해 금방 창을 닫은 사람도 도움이 되는 웹이라고 생각했으면 좋겠습니다. 비록 투박한 화면이지만 말입니다.
국민 청원 게시판을 크롤링할 때 Selenium을 이용하여 크롤링했습니다. 하지만 이 방식은 시간이 오래걸리죠. 자바를 이용하여 웹이 작성된 것으로 보이고 이 방식은 request 방법으로 Selenium 보다 훨씬 빨리 크롤링할 수 있다고 하더라고요. 이 방법에 대해 공부해야겠습니다. (이 부분에 대해 알고 계시는 분이 있다면 관련 자료를 공유해주시면 정말 감사합니다. 최고:-D)
코드
'개인 > 프로젝트' 카테고리의 다른 글
| Youtube 인기 급상승 동영상 Analysis (1) (10) | 2021.03.22 |
|---|---|
| [Kaggle 필사] DieTanic 데이터로 EDA 필사하기!! (0) | 2021.02.02 |
| [프로젝트] 이탈할 고객을 예측하여 수익 감소 방지하기 (0) | 2021.01.30 |
| 코멘토 SQL 입문부터 활용까지 후기 (0) | 2021.01.12 |