2021. 2. 2. 19:42ㆍ개인/프로젝트
지난 2020년 10월 한국정보화진흥원에서 개최한 2020 데이터 크리에이터 캠프에 참가하면서 EDA의 중요성을 느꼈다. 모델링 예측도 중요하지만 데이터 탐색에 대한 질문을 많이 해주시면서 중요성을 언급해주셨다. 우리 팀을 담당한 멘토님께 EDA 실력을 키우기 위한 자문을 구했을 때 Kaggle에 EDA를 주로 파서 꼼꼼하게 작성해놓은 글들이 많다. 참고하고 연습해서 키우는 것 밖에 없다.라는 답변을 얻고 Kaggle에서 EDA를 필사하고 분석 프로젝트에 적용해보기 위한 스터디를 만들었다. EDA는 데이터 특성마다 방법이 다르기 때문에 분류, 회귀, 군집화, 이미지 처리 순으로 한 달씩 기간을 잡아 프로젝트를 진행한다.
지난 1월은 분류를 위한 EDA를 필사하고 고객 이탈 분석 프로젝트를 진행했고 DieTanic 데이터로 EDA를 필사한 후 정리한 내용이다. 참고한 글은 이곳을 클릭하여 확인할 수 있다. 분석 배경부터 EDA 후 해석에 대한 설명이 매우 자세하기 때문에 필사하기에 매우 좋은 글이다. (영어로 된 글을 직접 해석하며 필사했기 때문에 잘못된 정보가 있다면 지적 부탁드립니다.)
순서
1. 분석 배경
2. 데이터 설명
3. 데이터 탐색(EDA)
4. EDA 내용을 기반으로 데이터 전처리
5. 알게 된 점
💻 사용한 언어: Python
1. 분석 배경

타이타닉 침몰은 역사에서 가장 악명 높은 조난 사고 중 하나이다. 1912년 4월 15일, 타이타닉 호는 빙산과 충돌하여 2224명의 승객과 승무원 중 1501명이 사망하였다. 이름이 DieTanic인 이유이다. 이것은 매우 불행한 재앙이다. 전 세계 그 누구도 잊을 수 없는. 어떤 사람들이 생존할 가능성이 높은가에 대한 모델을 구축하는 것이 목표이다.
2. 데이터 설명
타이타닉 데이터는 데이터 사이언스를 시작하는 사람들에게 매우 좋은 데이터셋이다. 데이터 변수들은 아래와 같고 Survived 변수가 종속 변수이다.

3. 데이터 탐색
import numpy as np
import pandas as pd # 데이터프레임을 다루기 위해
import missingno as msno # 결측치 처리를 위해
# 시각화ㅏ
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight') # 테마 설정
%matplotlib inline # 주피터 백엔드를 사용하겠다는 의미
import warnings
warnings.filterwarnings('ignore') # 경고 출력 안함. data = pd.read_csv('data/titanic/train.csv')
print("Data shape{}".format(data.shape))
print("-"*85)
print("Data head\n{}".format(data.head()))
print("-"*85)
print("Data summary\n{}".format(data.describe()))
print("-"*85)
print("Data Info\n{}".format(data.info()))
데이터는 891개의 행과 12개의 변수로 이루어져 있고 summary결과를 통해 각 변수마다 데이터 값의 범위가 크다는 것을 알 수 있다. summary는 수치형 변수에 대한 정보만을 요약해준다. Age 변수의 개수가 714개인 것으로 보아 결측치가 존재하는 것 같다.

info의 결과를 봤더니 Age 변수뿐만 아니라 Cabin, Embarked 변수에도 결측치가 있다. Name, Sex, Ticket, Cabin, Embarked 변수들은 범주형 변수이고 나머지는 수치형 변수이다. PassengerId는 독립 변수로 사용하기에 부적절하므로 사용하지 않을 것이다.
missingno 라이브러리를 이용하면 결측치를 시각화할 수 있다. 결측치가 있는 곳을 흰색으로 나타내고 가장 오른쪽의 막대는 변수에 상관없이 결측치가 있는 행을 흰색으로 표시해놓은 것이다.
msno.matrix(data,figsize=(12,5))

결측치 수를 직접 확인하고 싶다면 isnull 메서드를 적용한 후 sum()을 이용하면 True인 것들만 합하여 결측치 수를 반환한다. Cabin에 매우 많은 결측치가 존재한다. 이런 결측치들은 제거, 대체와 같은 전처리 작업이 필요하다.
data.isnull().sum() 
종속 변수인 생존 유무 변수를 시각화를 통해 한눈에 볼 수 있도록 해보겠다. 파이 그래프와 막대그래프를 이용하여 생존율과 사망률, 생존자 수와 사망자 수를 파악한다.
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('생존율과 사망율')
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('생존자 수와 사망자 수')
plt.show()
승객 891명 중 약 350명(38.4%)만이 살아남았다. 데이터로부터 더 나은 통찰력을 얻고 승객 중 어떤 류의 사람들이 살았고 그렇지 못했는지 봐야 한다. 이 데이터셋에는 다른 변수들이 있으므로 변수 유형에 대해 살펴본다.
변수의 유형
변수는 범주형 변수, 순서형 변수, 연속형 변수가 있다.
범주형 변수는 성별과 같이 2개 이상의 범주를 가지는 변수로 각각의 값으로 feature가 카테고리화 된다. 순서형 변수는 말 그대로 순서를 가지는 변수로 설문조사 시 1점, 2점, 3점과 같은 변수이다. 어떤 변수가 특정 두 지점, 혹은 최댓값과 최솟값 사이에 어떤 값이든 가질 수 있다면 이를 연속형 변수라고 한다.
각 변수별로 EDA를 진행한다.
Sex
성별 변수는 범주형 변수로 막대그래프를 이용하여 비교할 수 있다.
f,ax=plt.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[1])
ax[1].set_title('성별에 따른 생존율')
sns.countplot('Sex',hue='Survived',data=data,ax=ax[0])
ax[0].set_title('성별에 따른 생존자 수 vs 사망자 수')
plt.show()
왼쪽 시각화를 통해 배에 타고 있는 사람들의 수는 남자들이 여자들보다 훨씬 많다. 하지만 성별에 따른 생존율을 확인해보았을 때 여성은 75%, 남성은 18-19%로 여자들의 생존율이 훨씬 높다. 이는 추후 중요한 변수로 사용할 수 있다.
Pclass
Pclass 변수는 티켓 클래스로 순서형 변수이다. 분할표로 확인해보았을 때 티켓 클랙스가 3인 경우 가장 많이 사망했다.
pd.crosstab(data.Pclass,data.Survived,margins=True).style.background_gradient(cmap='summer_r')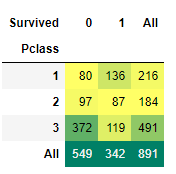
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0])
ax[0].set_title('Pclass에 따른 탑승객 수')
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Pclass에 따른 생존자 수 vs 사망자 수')
plt.show()
시각화를 통해서도 Pclass가 3으로 낮은 등급의 티켓을 구매한 사람들이 많고 1, 2 순으로 구매한 사람들이 많다. 3을 구매한 사람들은 생존자 수와 사망자 수의 차이가 매우 크며 사망자수가 훨씬 많고 중간 등급인 2를 구매한 사람은 사망자가 더 많긴 하지만 비슷한 수치이다. 하지만 가장 높은 등급인 1을 구매한 사람들의 경우 생존자 수가 사망자수보다 많다. 이를 보고 비싼 티켓을 구매한 사람들에게 생존의 기회가 먼저 주어졌다는 것을 알 수 있다.
성별과 티켓 클래스, 생존 여부를 함께 보겠다. PClass가 1인 사람들 중 여성은 3명이 죽고 91명이 살았지만 전체적으로 Pclass에 상관없이 여성은 우선적으로 생존의 기회가 주어졌다.
pd.crosstab([data.Sex,data.Survived],data.Pclass,margins=True).style.background_gradient(cmap='summer_r')
sns.factorplot('Pclass','Survived',hue='Sex',data=data)
plt.show()
시각화로 표현하면 남성의 생존율과 여성의 생존율의 차이가 큰 것을 알 수 있고 Pclass에 따라 생존율이 다르다는 것이 확연히 보인다.
Age
나이 변수는 연속형 변수이다. 가장 나이가 어린 승객은 0.42세, 가장 나이가 많은 승객은 80세로 평균 승객의 나이는 약 30세이다.
print('Oldest Passenger was of:',data['Age'].max(),'Years')
print('Youngest Passenger was of:',data['Age'].min(),'Years')
print('Average Age on the ship:',data['Age'].mean(),'Years')
연속형 변수는 바이올린 플롯으로 나타낼 수 있다. 바이올린 플롯은 각 class별 전체적인 분포를 비교하는데 좋은 시각화이다.
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age", hue="Survived", data=data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age", hue="Survived", data=data,split=True,ax=ax[1]) # 바이올린 플롯
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
Pclass에 따라 나이에 차이가 있어 보인다. Pclass 등급이 낮아짐에 따라 어린이의 수가 증가한다. 그중 10세 미만의 생존율이 Pclass1을 제외하고는 좋아 보인다. 20-50세 사이의 Pclass1 탑승객 생존율이 높고 여성의 경우 매우 높은 것으로 보인다. 남성은 여성에 비해 나이가 많을수록 더 많이 사망했고 여성은 전체적으로 생존률이 높으나 20대-40대에 생존률이 높다.
177개의 결측치가 존재했기 때문에 이 값을 처리할 방안이 필요하다. 외국은 Mr, Mrs와 같이 이름 앞에 호칭을 붙인다. 이를 이용하여 결측치를 대체할 것이다.
data.Name[1:5]
먼저 Name 변수에서 Mrs, Miss와 같은 호칭을 추출한다.
data['Initial']=0
for i in data:
data['Initial']=data.Name.str.extract('([A-Za-z]+)\.') #lets extract the Salutations
data['Initial']
추출된 호칭을 확인하면 Capt, Col과 같이 알 수 없는 호칭들도 있다.
pd.crosstab(data.Initial,data.Sex).T.style.background_gradient(cmap='summer_r') #Checking the Initials with the Sex
알 수 없는 호칭들은 Other로 Lady와 같은 호칭은 직접 Mrs와 같이 수정한다.
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','
Jonkheer','Col','Rev','Capt','Sir','Don'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],
inplace=True)data.groupby('Initial')['Age'].mean() #lets check the average age by Initials
호칭 별 평균 나이를 이용하여 결측치 값을 대체한 후 시각화로 나타낸다.
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46
data.Age.isnull().any() # 결측치 없음.f,ax=plt.subplots(1,2,figsize=(20,10))
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
data[data['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived= 1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()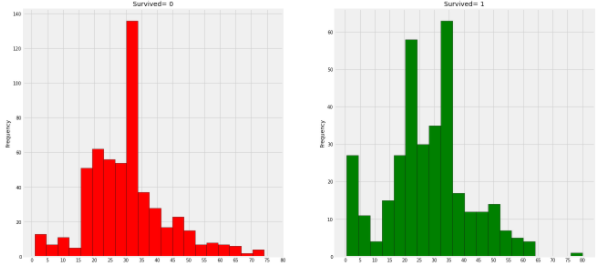
생존 여부 별 나이 분포를 확인했을 때 5세 이하 어린이들이 많이 생존하였고 최고령 구매 승객은 80세, 최대 사망자수는 30-40세에 분포해있다. (y축의 범위가 다름을 확인)
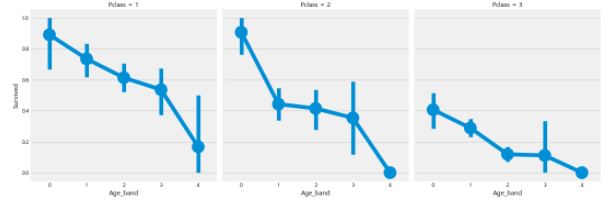
Pclass와 나이에 따라 생존율을 비교해보았을 때 Pclass에 관계없이 여성(Mrs, Miss)과 어린이(Master)의 생존율이 높다.
sns.factorplot('Pclass','Survived',col='Initial',data=data)
plt.show()
Embarked
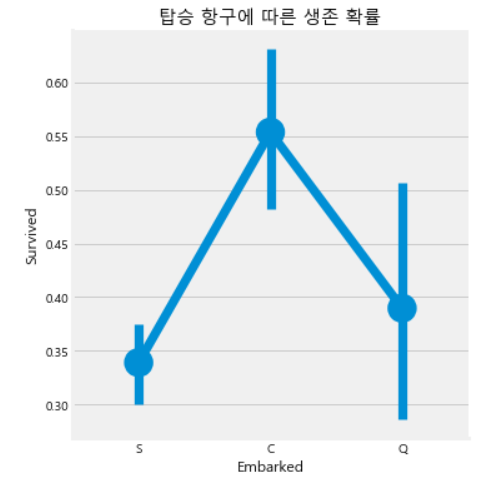
탑승 항구 변수는 범주형 변수이다. 분할표와 factor plot을 통해 보았을 때 탑승 항구에 따른 생존율은 S가 가장 낮고 C의 생존율이 가장 높다.
pd.crosstab([data.Embarked,data.Pclass],[data.Sex,data.Survived],margins=True).style.background_gradient(cmap='summer_r')
sns.factorplot('Embarked','Survived',data=data, ax=ax)
plt.title("탑승 항구에 따른 생존 확률")
plt.show()
f,ax=plt.subplots(2,2,figsize=(20,15))
sns.countplot('Embarked',data=data,ax=ax[0,0])
ax[0,0].set_title('No. Of Passengers Boarded')
sns.countplot('Embarked',hue='Sex',data=data,ax=ax[0,1])
ax[0,1].set_title('Male-Female Split for Embarked')
sns.countplot('Embarked',hue='Survived',data=data,ax=ax[1,0])
ax[1,0].set_title('Embarked vs Survived')
sns.countplot('Embarked',hue='Pclass',data=data,ax=ax[1,1])
ax[1,1].set_title('Embarked vs Pclass')
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()
S에서 가장 많은 승객이 탑승하였고 그 탑승객들의 대부분은 PClass 3 속한다. C에서 탑승한 승객은 생존율이 사망률보다 높았고 C에 Pclass승객들이 많이 있다. Q항구에서 탑승한 승객의 대부분은 Pclass 3에 속한다.
sns.factorplot('Pclass','Survived',hue='Sex',col='Embarked',data=data)
plt.show()
탑승 항구 별로 나눠봤을 때 생존율이 Pclass1, 2는 거의 비슷하게 1에 가깝고 탑승 항구가 S일 때는 남성과 여성 모두 생존율이 다른 항구에 비해 낮다. 이를 통해 S 탑승 항구를 이용하고 Pclass가 3인 승객들은 다른 Pclass 승객들보다 생존의 기회가 적다는 것을 알 수 있다. 탑승 항구가 Q일 때 거의 모두 Pclass가 3인 승객들이기 때문에 여성에게 생존의 기회가 먼저 적용된 것을 생각하면 남성이 매우 불리하다.
결측치가 2개 있었는데 대부분의 승객들이 S 탑승구를 이용했기 때문에 S로 대체하여 사용한다. 이는 결측치를 최빈값으로 대체한 것이다.
data['Embarked'].fillna('S',inplace=True)
data.Embarked.isnull().any() # 결측치 없음.
SibSp & Parch
SibSp는 탑승한 승객이 형제자매 또는 배우자 몇 명과 함께 탔는지에 관한 변수, Parch는 부모 또는 자식 몇 명과 함께 탔는지에 대한 변수로 두 변수 모두 이산형 변수이다.
pd.crosstab(data.SibSp,data.Pclass).style.background_gradient(cmap='summer_r')sns.barplot('SibSp', 'Survived', data=data)

승객이 혼자 탑승했을 때 생존율이 35% 정도 되는 것으로 보이고 형제자매, 배우자의 수가 증가하면 생존율이 감소한다. 특히, 가족의 수가 5-8명인 경우 생존율이 0%이다. Pclass를 확인해보았을 때 모두 3에 속했고 사망했다.
pd.crosstab(data.Parch, data.Pclass).style.background_gradient(cmap='summer_r')sns.barplot('Parch', 'Survived', data=data)
부모와 아이가 함께 탑승한 승객들의 생존율이 높지만 그 수가 증가할수록 생존율이 낮아진다. 혼자 탑승하는 경우 생존하기 어렵고 가족이 4명 이상인 경우 생존율이 감소한다.
Fare
요금에 관한 변수로 연속형 변수이다. 가장 낮은 요금은 0, 가장 높은 요금은 512, 평균은 32이다. 이에 대한 분포를 히스토그램을 이용하여 확인한다. 히스토그램은 수치형 변수들을 탐색할 때 매우 좋은 시각화이다.
print('Highest Fare was:',data['Fare'].max())
print('Lowest Fare was:',data['Fare'].min())
print('Average Fare was:',data['Fare'].mean())
f,ax=plt.subplots(1,3,figsize=(20,8))
sns.distplot(data[data['Pclass']==1].Fare,ax=ax[0])
ax[0].set_title('Fares in Pclass 1')
sns.distplot(data[data['Pclass']==2].Fare,ax=ax[1])
ax[1].set_title('Fares in Pclass 2')
sns.distplot(data[data['Pclass']==3].Fare,ax=ax[2])
ax[2].set_title('Fares in Pclass 3')
plt.show()
Pclass가 1인 경우 요금의 분포가 넓게 퍼져있고 Pclass가 2인 경우 요금의 분포가 1에 비해 좁아진다. Pclass가 3인 경우는 다른 등급에 비해 더 좁게 분포하고 0-30 사이에 몰려있다. 연속형 변수이기 때문에 binning을 통해 이산형 값들로 변환하여 사용할 수 있다.
전체 featrue eda 탐색 결과
- Sex
- 남성보다 여성의 생존율이 높다.
- Pclass
- 1 클래스 승객에게 생존율이 높고 3 클래스의 생존율이 낮다.
- 여성들의 생존율이 Pclass가 1 또는 2일 때 거의 1로 높다.
- Age
- 5-10세 미만 아이들은 높은 생존율을 갖고 있다
- 15-35세 사이의 승객들이 많이 사망한다.
- Embarked
- C의 생존율이 사망률보다 높았고 이는 Pclass1번이 많았기 때문이다.
- Parch+SibSp
- 1-2명의 형제자매, 배우자가 같이 탑승하고 있거나 1-3명의 부모와 함께 탑승했을 때 생존율이 혼자 탑승했거나 대가족이 탑승한 사람들의 생존율보다 더 높다.
모델링에 적용하기 전 변수별 상관관계를 확인해본다.
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
종속변수와 가장 높은 상관관계를 보이는 변수는 Pclass 변수로 음의 상관관계를 갖고 있다. Pclass와 Fare 변수는 높은 음의 상관관계를 갖고 있고 SibSp와 Parchi 변수의 상관계수 값은 0.41이지만 다중공선성에 문제 되는 상관계수 값은 아니다. 이로써 모든 feature를 모델링할 때 사용할 수 있다.
4. EDA 내용을 기반으로 데이터 전처리
Feature Engineering 모델링할 때 데이터셋의 모든 변수가 필요한 것은 아니고 불필요한 변수가 존재하거나 추가할 변수가 있을 수 있는데 이를 하는 과정을 feature engineering이라고 한다.
Age 변수와 같은 연속형 변수로 category값으로 binning이나 normalization을 해줘야 한다. 연속형 변수들의 범위를 맞추어 모델이 변수를 동일한 가정 아래 취급하도록 만든다.
최고령이 80세였는데 0-80 범위를 5개의 빈으로 나누어 16(80/5) 사이즈 bin이 생겼다.
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
data.head(2)data['Age_band'].value_counts().to_frame().style.background_gradient(cmap='summer') #checking the number of passenegers in each bandsns.factorplot('Age_band','Survived',data=data,col='Pclass')
plt.show()
Parch변수와 SibSp의 요약을 위한 변수는 비슷한 속성을 갖고 있는 변수이기 때문에 Family size & Alone 변수로 보다 독립적이고 유용한 변수를 생성해주는 것이 좋다. 이 변수는 가족의 수와 생존율의 관계를 체크할 수 있는 변수라는 속성을 가진다.
data['Family_Size'] = 0
data['Family_Size'] = data['Parch'] + data['SibSp'] # Family_Size
data['Alone'] = 0
data.loc [data.Family_Size ==0, 'Alone'] = 1 # Alonesns.factorplot('Alone','Survived',data=data,hue='Sex',col='Pclass')
plt.show()
Pclass와 관계없이 혼자 탑승한 경우는 생존율이 낮지만 Pclass가 3인 여성의 경우 오히려 더 높다.
Fare 변수도 연속형 변수이기 때문에 4개의 구간으로 데이터를 분할한다. (binning)
data['Fare_Range'] = pd.qcut(data['Fare'], 4) # 4개 구간으로 데이터 분할
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r')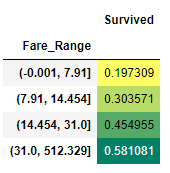
data['Fare_cat'] = 0
data.loc[data['Fare'] <= 7.91, 'Fare_cat'] = 0
data.loc[(data['Fare'] > 7.91) & (data['Fare']<=14.454), 'Fare_cat'] = 1
data.loc[(data['Fare'] > 14.454) & (data['Fare']<=31), 'Fare_cat'] = 2
data.loc[(data['Fare'] > 31) & (data['Fare']<=513), 'Fare_cat'] = 3sns.factorplot('Fare_cat', 'Survived', data=data, hue='Sex')
plt.show()
Fare_cat이 증가할수록 생존율이 증가하고 Sex와 함께 모델링에 중요한 Feature가 될 것으로 예상하는 변수이다.
대부분의 모델들은 텍스트를 숫자로 변경해줘야 한다.
data['Sex'].replace(['male','female'], [0, 1], inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2], inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'], [0,1,2,3,4], inplace=True)불필요한 변수를 삭제한다. Cabin 변수는 결측치가 너무 많고 많은 승객에 따라 cabin값이 많기 때문에 사용하지 않는다. 파생변수를 만든 후 다시 상관관계를 확인한다.
data.drop(['Name', 'Age', 'Ticket', 'Fare', 'Cabin', 'Fare_Range', 'PassengerId'], axis=1, inplace=True)
sns.heatmap(data.corr(), annot=True, cmap='RdYlGn', linewidths=0.2, annot_kws={'size' : 20})
fig = plt.gcf()
fig.set_size_inches(15, 15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()
Survived와 관계가 가장 큰 변수는 Sex이고 그다음으로 Initial변수, SibSp, Family_size, Parch가 양의 상관관계를, Alone, Family size가 음의 상관관계를 갖고 있다. 전보다 더 높은 상관계수를 갖는 변수들이 보인다.
5. 알게 된 점
factorplot은 범주형 변수들의 막대형 차트를 라인처럼 나타내어 좀 더 비교하기 쉽게 나타낸 시각화로 막대형 차트와 함께 보면 좀 더 눈에 와 닿는 시각화를 할 수 있다. 연속형 변수는 카테고리화하여 새로운 변수로 사용할 수 있다. 하지만 수치 값이 분명 다른데 카테고리화를 하면 같은 구간 내 데이터는 동일한 값이라고 판단하기 때문에 데이터에 따라 고려할 부분이다. 필사를 하며 의문점이 들었던 부분은 범주형 변수들을 라벨 인코딩하는 과정이다. Embarked와 initial 변수는 순서를 갖고 있는 변수가 아니기 때문에 원핫인코딩이 필요하다고 생각하는데 참고한 글에서는 라벨 인코딩을 진행해서 각 범주에 값의 차이가 있도록 만들었다. 이 의문점을 풀어줄 수 있는 사람을 적극 환영한다.
'개인 > 프로젝트' 카테고리의 다른 글
| Youtube 인기 급상승 동영상 Analysis (1) (10) | 2021.03.22 |
|---|---|
| [프로젝트] 국민 청원 게시판의 분산되는 동의 수, 이제 그만- (0) | 2021.01.30 |
| [프로젝트] 이탈할 고객을 예측하여 수익 감소 방지하기 (0) | 2021.01.30 |
| 코멘토 SQL 입문부터 활용까지 후기 (0) | 2021.01.12 |