2021. 3. 22. 00:10ㆍ개인/프로젝트
이번 글은 Youtube 인기 급상승 동영상을 분석하기 위해 인기 급상승 동영상 데이터를 수집할 것입니다.
순서
1. 분석 배경
2. 데이터 수집
3. selenium 알아보기
3.1. 웹요소 접근 메소드
3.2. 액션 체인
3.3. BeautifulSoup과 Selenium
3.4. 자바스크립트로 동작시키는 방법
3.5. Headless 모드
1. 분석 배경
유튜브 인기 급상승 동영상은 다양한 시청자의 관심을 끄는 영상으로 크리에이터의 다양성을 보여주는 영상, 흥미와 새로움을 느낄 만한 영상이 업로드됩니다. 조회수, 동영상 조회수 증가 속도, Youtube 외부를 포함하여 조회수가 발생하는 소스, 동영상 업로드 기간, 해당 동영상을 같은 채널에 최근 업로드한 다른 동영상과 비교한 결과를 고려하여 약 15분마다 업데이트됩니다.
인기 급상승 동영상을 분석하는 것은 사회적 이슈 및 트렌드를 파악할 수 있고 노출량을 높이기 위한 영상 제작 소재에 도움을 주기 때문에 주기적으로 변하는 인기 급상승 동영상을 분석해보고자 합니다.
2. 데이터 수집
이를 위해 데이터 수집을 진행하겠습니다. youtube 인기 급상승 동영상의 url을 먼저 받은 후 영상들의 제목, 좋아요 수, 싫어요 수, 채널명, 구독자수, 해시태그 등을 수집하겠습니다.

먼저, 필요한 라이브러리를 import 해줍니다. BeautifulSoup이 Selenium보다 간단하게 사용할 수 있지만 youtube 웹은 동적으로 움직여서 데이터를 수집해야 하므로 selenium 라이브러리가 필요하고 로딩 시간으로 인해 시간을 제어해야 합니다. 시간을 제어하는 방법에는 implicitly_wait 함수를 사용하여 처음에 한 번만 설정하여 찾으려는 웹 요소가 없을 때마다 최대 몇 초 기다릴 것인지 지정해주는 암시적인 방법(implicit wait)과 필요한 모든 요소가 정확히 어떤 상태가 될 때까지 기다릴 것인지, 최대 몇 초 기다릴 것인지 일일이 정해주는 명시적인 방법(explicit wait)이 있습니다. implicit wait 방법과 explicit wait 방법 둘 다 사용하는 것은 권장되지 않습니다.(참고) 저는 명시적인 방법을 이용하여 시간을 절약하기 위해 관련 모듈들을 import 합니다.
수집한 데이터는 DB에 저장하기 위해 필요한 모듈을 import 합니다.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait # wait 기간 설정
from selenium.webdriver.support import expected_conditions as EC # wait에 대한 조건 설정
import psycopg2
import re
웹 드라이버를 생성하기 위해 크롬 버전과 맞는 드라이버를 다운로드한 후 경로를 설정합니다. 만약 해당 드라이버가 있는 경로를 일일이 입력해주기 귀찮다면 'C:\Window'에 넣어놓으면 따로 호출하지 않고도 사용할 수 있습니다.
# driver = webdriver.Chrome(r"D:\chromedriver_win32\chromedriver.exe") # 경로 설정
driver = webdriver.Chrome() # 경로를 매번 설정하는 것이 귀찮다면 C:\Windows에 넣어주면 됨.
driver.maximize_window()
url = "https://www.youtube.com/feed/trending"
driver.get(url)
웹 요소에 접근하고 제어하며 인기 급상승 동영상의 url과 재생시간을 수집합니다.
video_href_lst = []
for video_tag in driver.find_elements_by_css_selector("#video-title"):
video_href_lst.append(video_tag.get_attribute("href")) # 속성으로 접근
# 인기급상승동영상 재생시간
video_time_lst = []
for video_time in driver.find_elements_by_css_selector("#overlays > ytd-thumbnail-overlay-time-status-renderer > span"):
video_time_lst.append(video_time.get_attribute("aria-label")) # 속성으로 접근
DB에 수집한 데이터를 바로 저장하기 위해 db와 연결하고 수집과 저장을 실행합니다. 로딩 시간으로 인해 앞서 import 했던 모듈들을 이용하여 wait를 설정합니다.
# PASSWORD = 비밀번호
conn = psycopg2.connect(host='localhost', dbname='YOUTUBE', user='postgres', password = PASSWORD, port='5432')
cursor = conn.cursor()
count = 0
for video_url in video_href_lst[0:50]: # 최근인기동영상이 함께 수집되기 때문에 50개만
driver.get(video_url)
title = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, '#container > h1 > yt-formatted-string'))).text
view_count = driver.find_element_by_css_selector('#count > ytd-video-view-count-renderer').text
view_count = int(re.sub("조회수 |,|회", "",view_count))
view_time = video_time_lst[count]
like = driver.find_elements_by_css_selector('a > #text')[0].get_attribute("aria-label")
like = int(re.sub("좋아요 |,|개", "", like))
dislike = driver.find_elements_by_css_selector('a > #text')[1].get_attribute("aria-label")
dislike = int(re.sub("싫어요 |,|개", "", dislike))
date = driver.find_element_by_css_selector('#date > yt-formatted-string').text
channel_name = driver.find_element_by_css_selector('#text > a').text
try:
owner_sub_count = driver.find_element_by_css_selector('#owner-sub-count').text
except: # 구독자 수 공개를 하지 않는 채널 존재
owner_sub_count = ''
try: # 더보기 클릭
driver.find_element_by_css_selector('#more').click()
except:
print(count)
description = driver.find_element_by_css_selector('#description > yt-formatted-string').text.replace("\n", "")
hashtags = []
for hashtag in driver.find_elements_by_css_selector('#description > yt-formatted-string > a'):
if "#" in hashtag.text:
hashtags.append(hashtag.text)
hashtags = ' '.join(hashtags)
url_code = video_url.split("=")[1]
query = "INSERT INTO youtube_pop (title, view_count, video_time, like_count, dislike_count, date, channel_name, owner_sub_count, description, hashtags, url_code) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);"
data = (title, view_count, view_time, like, dislike, date, channel_name, owner_sub_count, description, hashtags, url_code)
cursor.execute(query, data)
count += 1
conn.commit()
conn.close()
driver.quit()
최근 브레이브 걸스의 인기로 인해 인기급상승 동영상에 대부분 브레이브걸스의 영상들이 많네요,,,
3. selenium 알아보기
3.1. 웹요소 접근 메소드
selenium은 웹드라이버를 이용하여 컴퓨터에게 마우스 클릭이나 키보드 입력과 같은 동작을 인간 대신 처리하는 것입니다. 유튜브 데이터를 수집하면서 css 선택자를 사용하는 메소드로 find_element_by_css_selector()을 사용했지만 이외에도 다양한 메소드들을 제공하고 있습니다.
- tag 이름으로 접근
- driver.find_element_by_tag_name("태그명")
- id로 접근
- driver.find_element_by_id('id 명")
- css 선택자로 접근하는 것이 아니기 때문에 '#'을 제외하고 id 명만 입력해야 합니다.
- class로 접근
- driver.find_element_by_class("class명")
- id로 접근하는 것과 마찬가지로 '.'없이 class 명만 입력합니다.
- xpath로 접근
- driver.find_element_by_xpath("xpath경로")
- 앵커 태그에 사용되는 텍스트로 접근
- driver.find_element_by_partial_link_text("앵커태그에 사용되는 텍스트")
driver.find_element_by_ 까지는 동일하고 어떻게 접근할 것인가만 추가해주면 되기 때문에 메소드들을 쉽게 사용할 수 있습니다. 만약 여러 개의 요소들을 가져오고 싶다면 driver.find_elements_by_css_selector 메소드를 사용하면 됩니다. 유튜브 데이터를 수집하는 코드를 보시면 인기 급상승 동영상의 url과 재생시간, 해시태그는 driver.find_elements_by_css_selector을 사용했지만 다른 정보들은 driver.find_elements_by_css_selector 메소드를 사용한 것을 확인할 수 있습니다. 이렇듯 하나의 요소만 가져올 때는 element, 여러 개의 요소들을 가져올 때는 elements를 사용하고 웹 요소 리스트를 반환받는다는 점을 기억합니다.
3.2. 액션 체인
click()과 같은 메소드는 액션 체인입니다. 액션 체인을 사용할 때는 먼저 필요한 웹 요소들을 찾아놓고 동작시켜야 합니다. click 뿐만 아니라 .double_click()을 이용하여 더블 클릭을 할 수 있고 .context_click()를 이용하여 우클릭을 할 수도 있습니다. 그외 .drag_and_drop(웹요소 클릭, 웹 요소까지 드래그), .move_to_element(element) 웹 요소까지 마우스를 움직이고 .send_keys(keys) 현재 선택된 웹 요소에 키보드로 입력값을 보내는 동작, 동작을 중지시키는 .pause(동작을 멈추는 시간) 등의 동작을 할 수 있습니다. (더 많은 동작들을 참고하세요.)
3.3. BeatifulSoup과 Selenium
Selenium은 BeatifulSoup과 같이 사용하는 것도 좋습니다. BeutifulSoup은 HTML 파싱에 최적화된 라이브러리로 다양한 문법들이 존재하고 간결합니다. 또한 파싱 작업에서는 Selenium보다 더 빠르고 효율적입니다. 스크래핑 중간중간에도 Selenium 동작이 필요한 경우 모든 작업을 Selenium으로 하는 것이 좋지만 그렇지 않은 경우라면 BeautifulSoup과 함께 사용해도 좋을 것 같습니다.
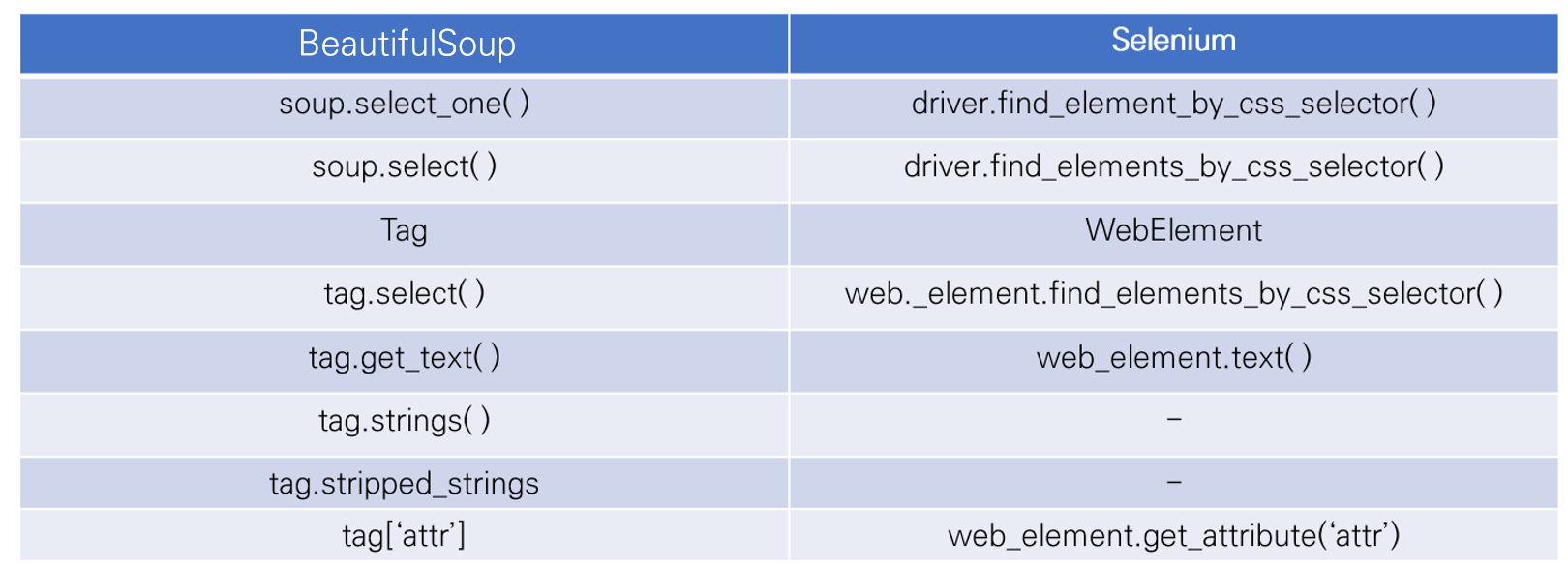
위 표에서 HTML 태그를 BeautifulSoup은 Tag, Selenium은 WebElement라고 부릅니다. BeautifulSoup은 HTML을 파싱 해서 HTML 태그의 내용을 보지만 Selenium은 HTML 태그에 해당하는 웹 요소와 상호 작용하기 때문에 웹 요소라고 부릅니다.
3.4. 자바스크립트로 동작시키는 방법
Selenium에서 웹사이트에서 스크롤하는 작업이나 웹 사이트의 내용이 바뀌는 작업들은 자바스크립트로 동작하는 것들로 자바스크립트 코드를 이용하여 웹을 동작시킬 수 있습니다.
driver.execute_script("window.scrollTo(0,200);")은 driver.execute_script 메소드는 자바스크립트 코드를 입력으로 받아 동작시키는 함수입니다. window.scrollTo는 (0, 200) 위치까지 스크롤하라는 것입니다. 현재 페이지에서 스크롤 마지막 위치를 알고 싶으면 driver.execute_script("return document.body.scrollHeight")를 이용하면 됩니다.
이외에도 CSS선택자가 아닌 원하는 텍스트의 값을 입력으로 받아 클릭할 수도 있습니다.
3.5. Headless모드
만약Selenium으로 하는 작업이 복잡하고 시간이 오래 걸린다면 웹브라우저가 눈에 보이지 않는 상태로 동작하는 Headless 모드를 사용할 수 있습니다. 백그라운드에서 실행되는 모드로 컴퓨터의 자원이 덜 소모되고 빠르게 동작합니다. 하지만 웹 브라우저가 눈에 보이지 않아 오류 메시지만으로 오류를 파악해야 하기 때문에 어느 지점에서 오류가 났는지 확인하는데 힘들 수도 있습니다. headless모드를 이용하는 방법은 아래와 같습니다.
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless")
options.add_argument("window-size = 1920,1080") # 브라우저 창의 크기를 충분히 크게 설정하여 원활하게 동작하도록
다음 글에 이어서 분석을 진행해보겠습니다.
selfkldgjalk)
'개인 > 프로젝트' 카테고리의 다른 글
| [Kaggle 필사] DieTanic 데이터로 EDA 필사하기!! (0) | 2021.02.02 |
|---|---|
| [프로젝트] 국민 청원 게시판의 분산되는 동의 수, 이제 그만- (0) | 2021.01.30 |
| [프로젝트] 이탈할 고객을 예측하여 수익 감소 방지하기 (0) | 2021.01.30 |
| 코멘토 SQL 입문부터 활용까지 후기 (0) | 2021.01.12 |